



前言
Ollama是一个开源的大模型管理工具,它提供了丰富的功能,包括模型的训练、部署、监控等。通过Ollama,你可以轻松地管理本地的大模型,提高模型的训练速度和部署效率。此外,Ollama还支持多种机器学习框架,如TensorFlow、PyTorch等,使得你可以根据自己的需求选择合适的框架进行模型的训练。
部署教程
下载
macOS:
https://ollama.com/download/Ollama-darwin.zip
Windows preview:
https://ollama.com/download/OllamaSetup.exe
Linux,直接运行:
curl -fsSL https://ollama.com/install.sh | sh
当然,ollama也支持docker部署。
本文主要介绍我在macOS上的本地部署过程。
安装
下载Ollama-darwin.zip后,解压,直接双击或将程序APP拖入应用程序即可,安装成功的话,就会出现可爱的羊驼图标:

安装模型
现如今开源的大模型已经越来越丰富了,通过ollama网站的模型库:
就可以看到相应列表:
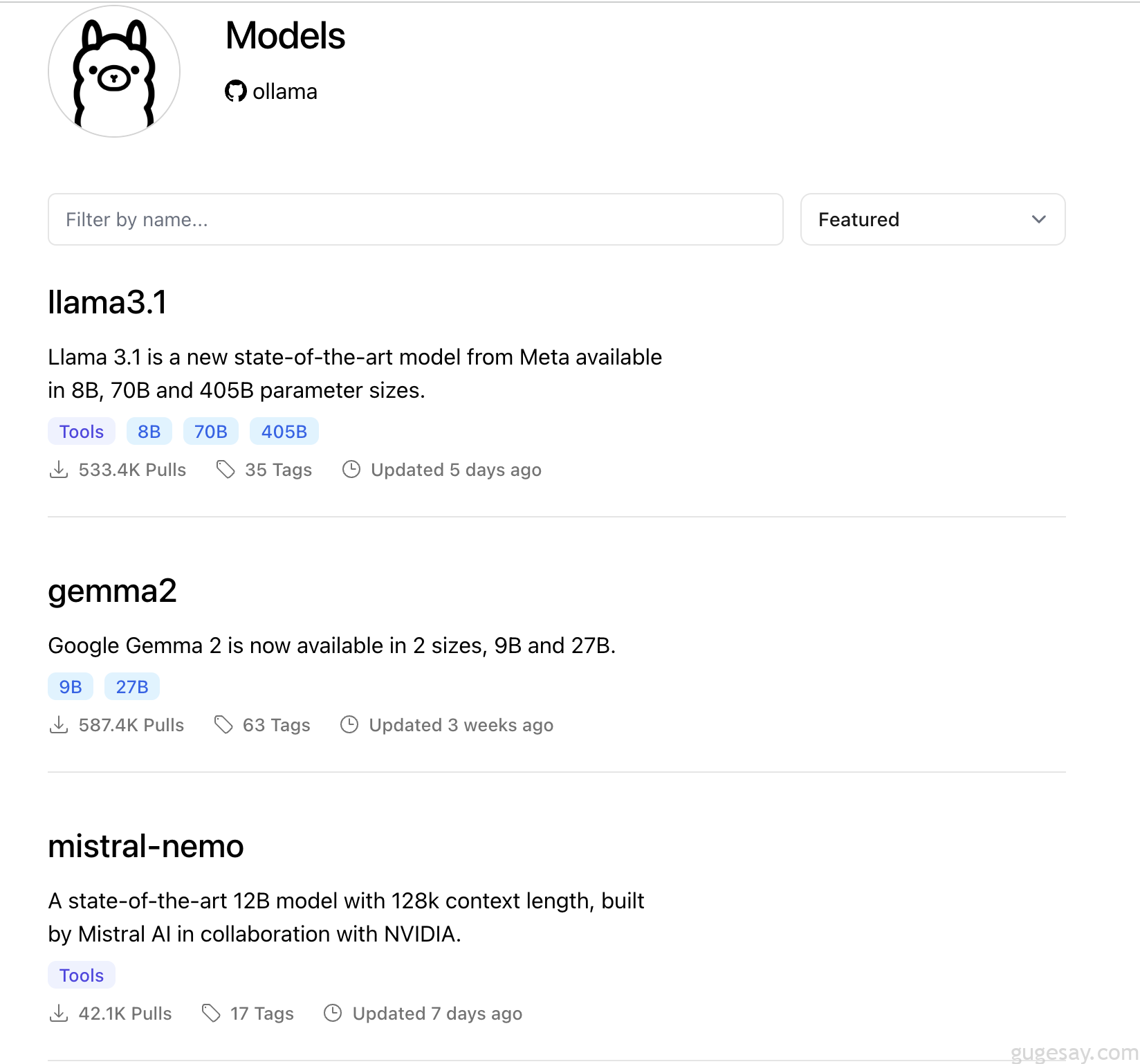
其中 Gemma 2 是 Google 公司最新的开源大语言模型,可以看到下载量587.4K,点击Gemma2后,可以看到该模型的具体信息:
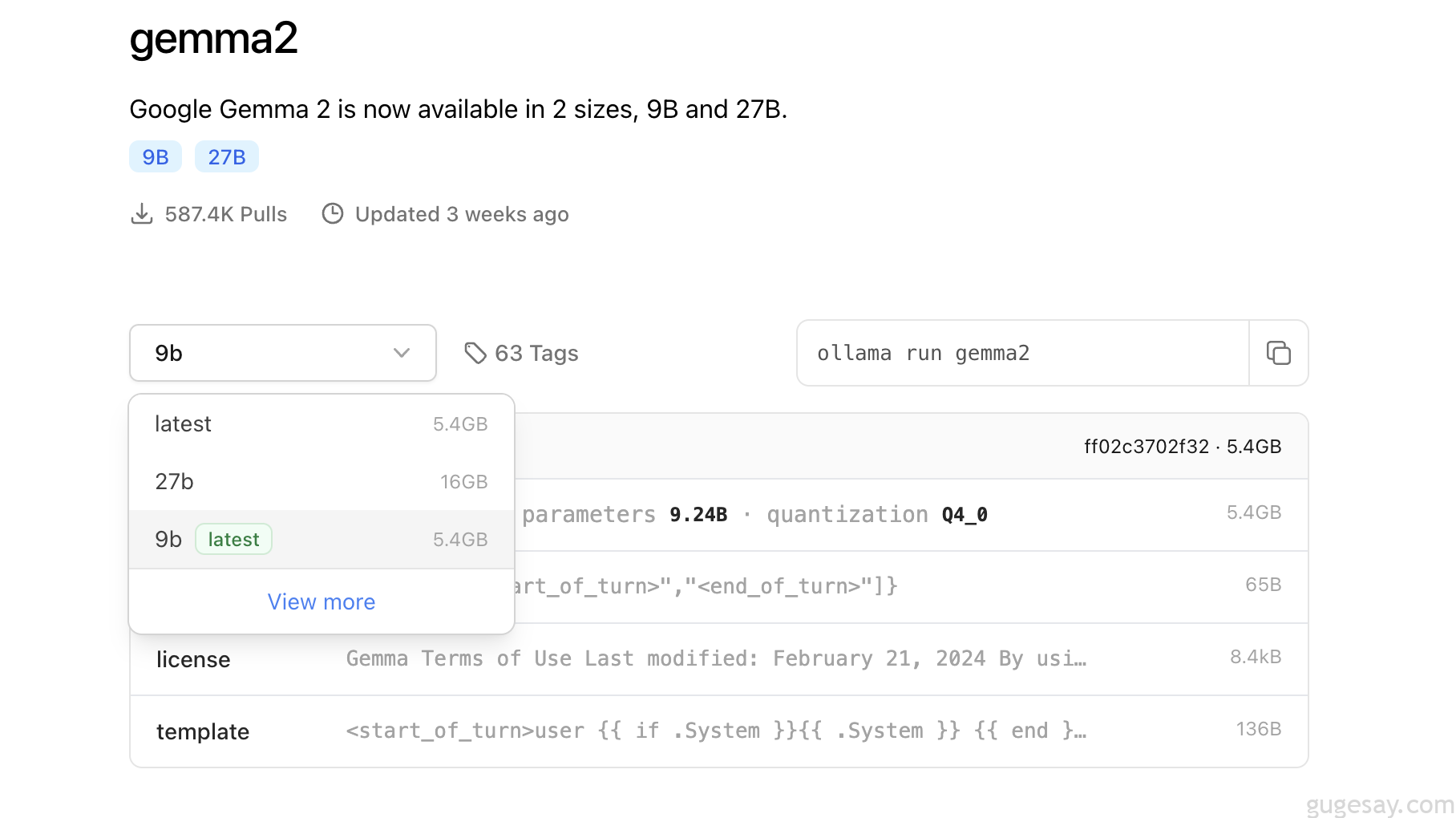
一时脑热,直接下载并安装了27b(27亿参数量):
ollama run gemma2:27b
结果成功运行后,回答一个问题需要1、2分钟才能蹦出几个字。后来上网一查,哭了:sob:

咳咳,只好退而求其次,乖乖选择9b:
ollama run gemma2:9b
使用
经过一段时间的等待后,成功下载并运行:

回复速度还是很快的,内存占用大概在90%(骨哥内存18G)左右。
安装其它模型的话,同上,比如骨哥还尝试安装了secgpt_chat(4亿参数量):
安装运行后和GPT-4o做了一下简单的对比,额,差的不是一点半点,想想也是,毕竟人家可是GPT-4o,这区区的4b模型怎么能比呢。
WebUI
总是通过命令行来提问总觉得不是很舒服,那就装个WebUI吧,ollama本身就提供WebUI,安装起来也非常简单,只需要6步:
- 下载并安装 Node.js 工具:https://nodejs.org/zh-cn
- 下载ollama-webui工程代码:
git clone https://github.com/ollama-webui/ollama-webui-lite ollama-webui
3.切换ollama-webui代码的目录:cd ollama-webui
4.设置 Node.js 下载提速:npm config set registry http://mirrors.cloud.tencent.com/npm/
5.安装 Node.js 依赖工具包:npm install
6.启动 Web 可视化界面:npm run dev
成功启动后,通过http://localhost:3000 即可访问
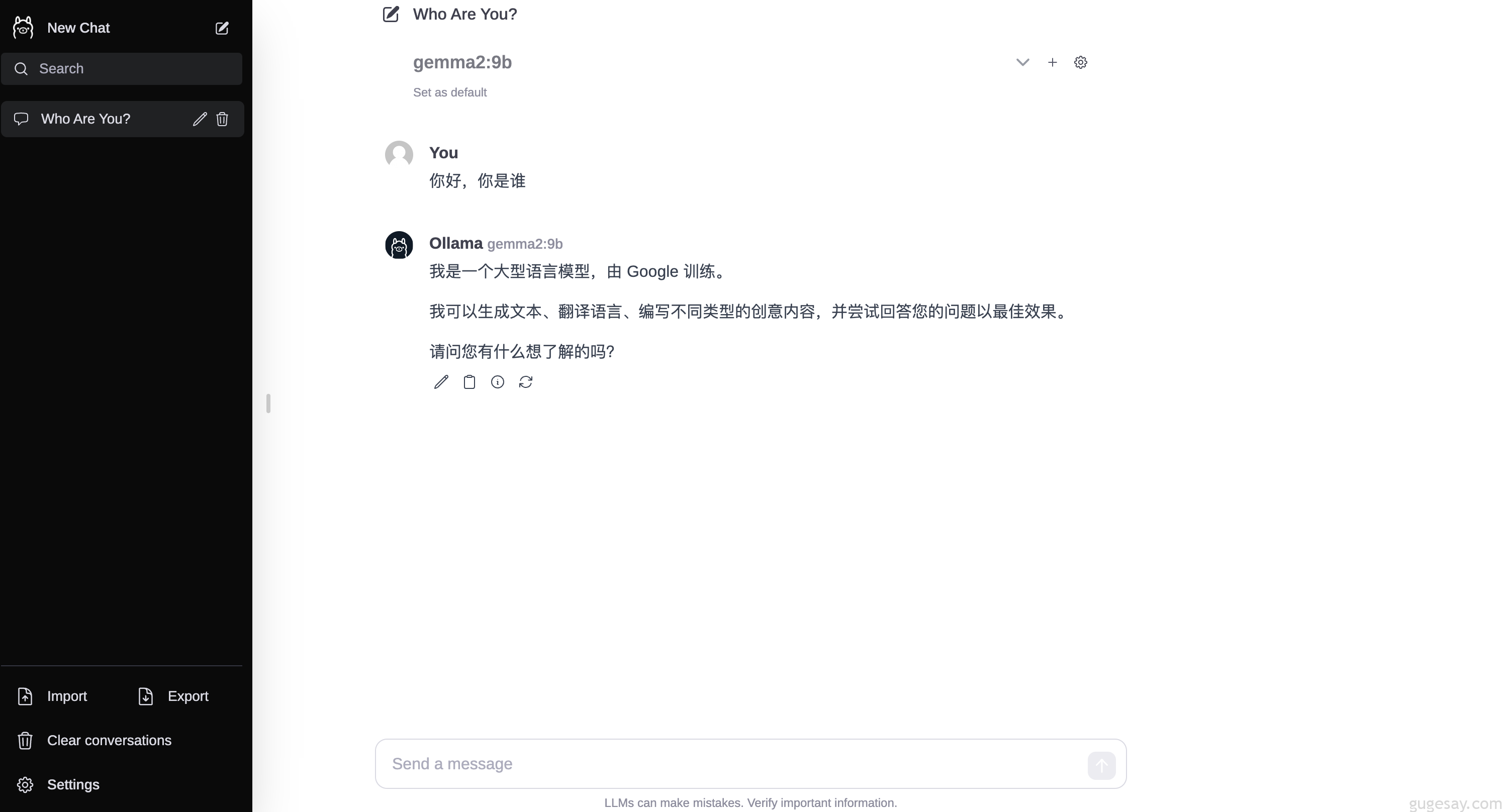
这一下就舒服多了~通过简单的对比,发现Gemma2用起来还是很不错的,至少可以满足一些基本需求了(比如生成代码、代码解释、简单的问答等等)。
省钱小妙招(插件使用本地Gemma2)
这两天骨哥使用了一款相当不错VScode插件–Aide,当时安装的时候,安装量还是10k,这两天已经飙到了14k+了:
这个插件的两大功能对我来说特别实用,一个是代码转换,一个是代码注释。
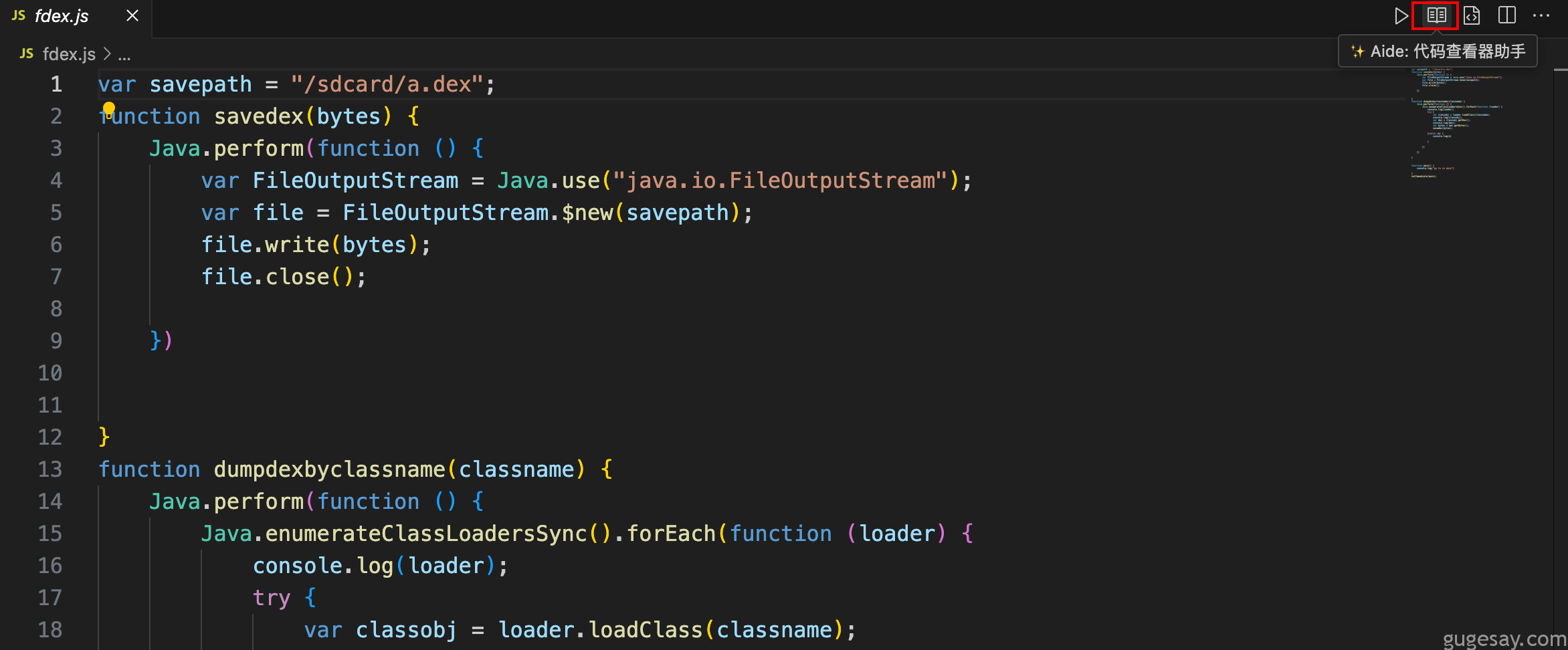
所谓代码转换,就是你可以利用该插件,调用AI接口,实现代码间的转换。比如你有一段JS代码,想要转换成Python代码,那么只要点击右上角的按钮,便可一键完成:
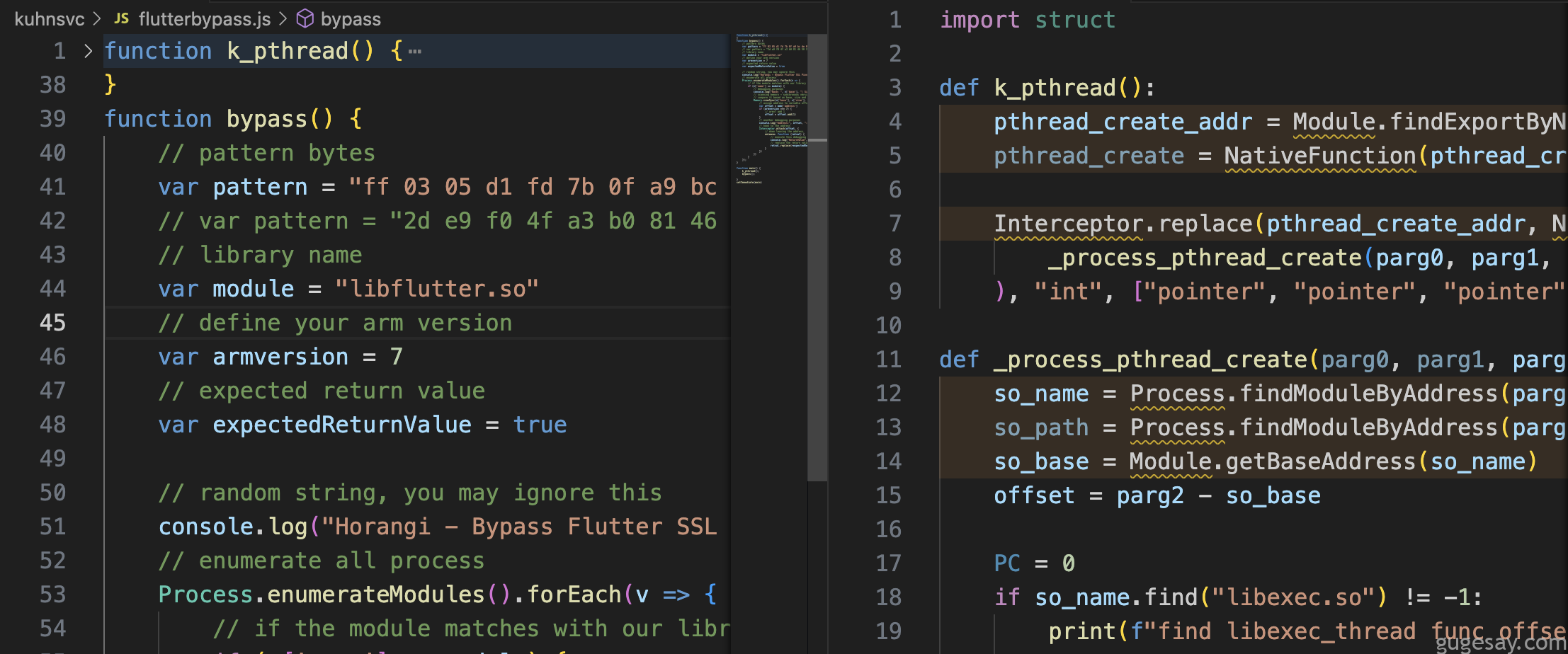
转换效果:
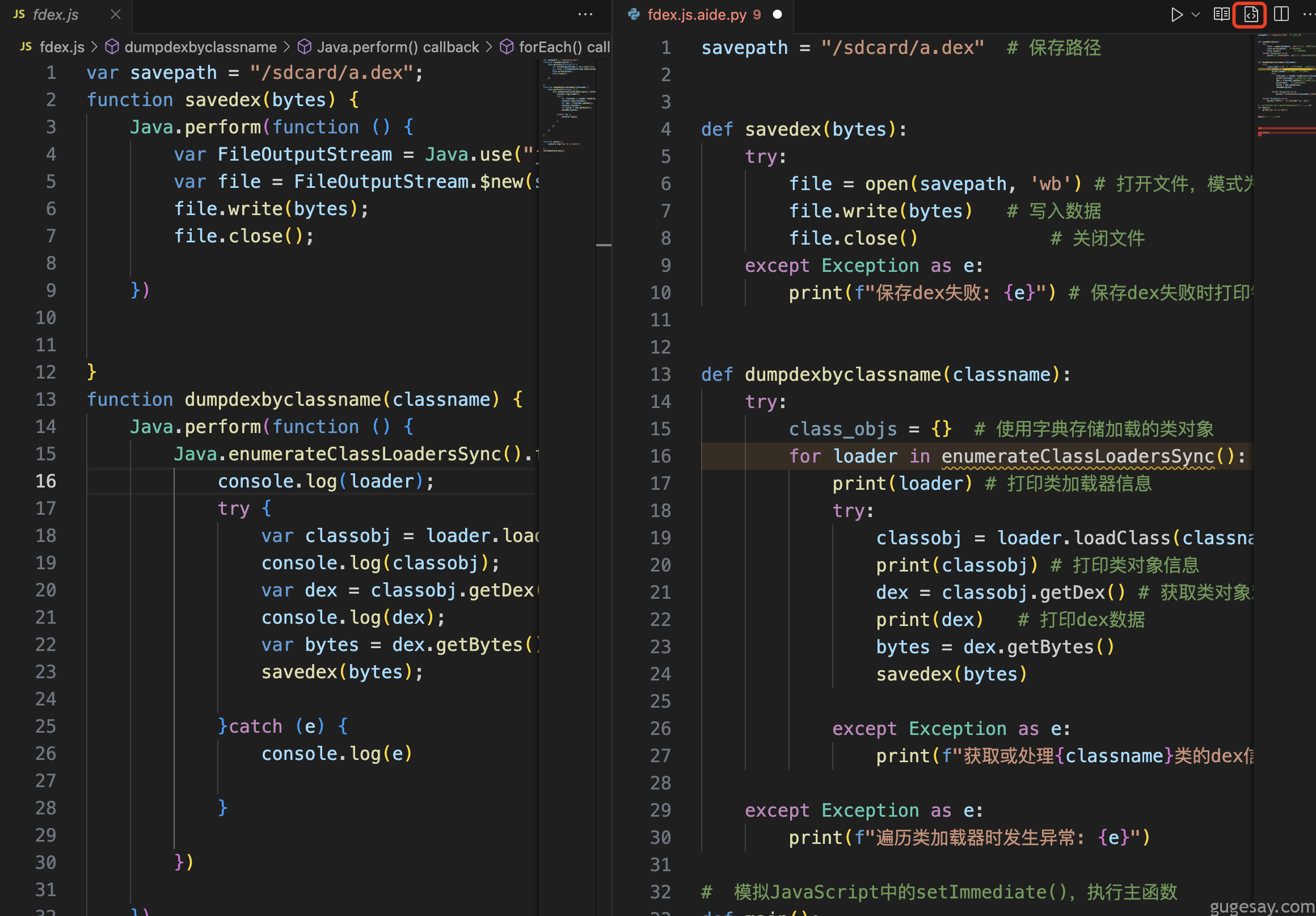
再看代码注释功能,同样右上角一键对代码进行注释,“妈妈再也不用担心我看不懂别人的屎山代码了”:
关于AI的API设置,如果使用诸如OpenAI的API Key,可参照如下设置:
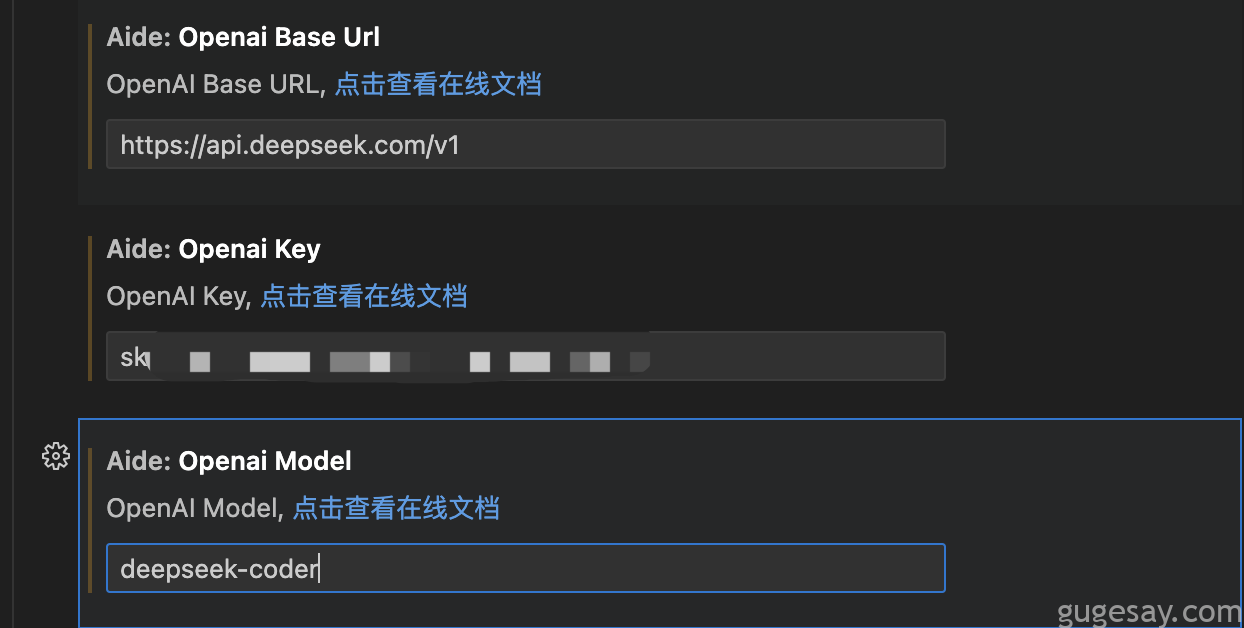
比如使用国内的某API已经算相对便宜了(几块钱就能用上百万tokens):
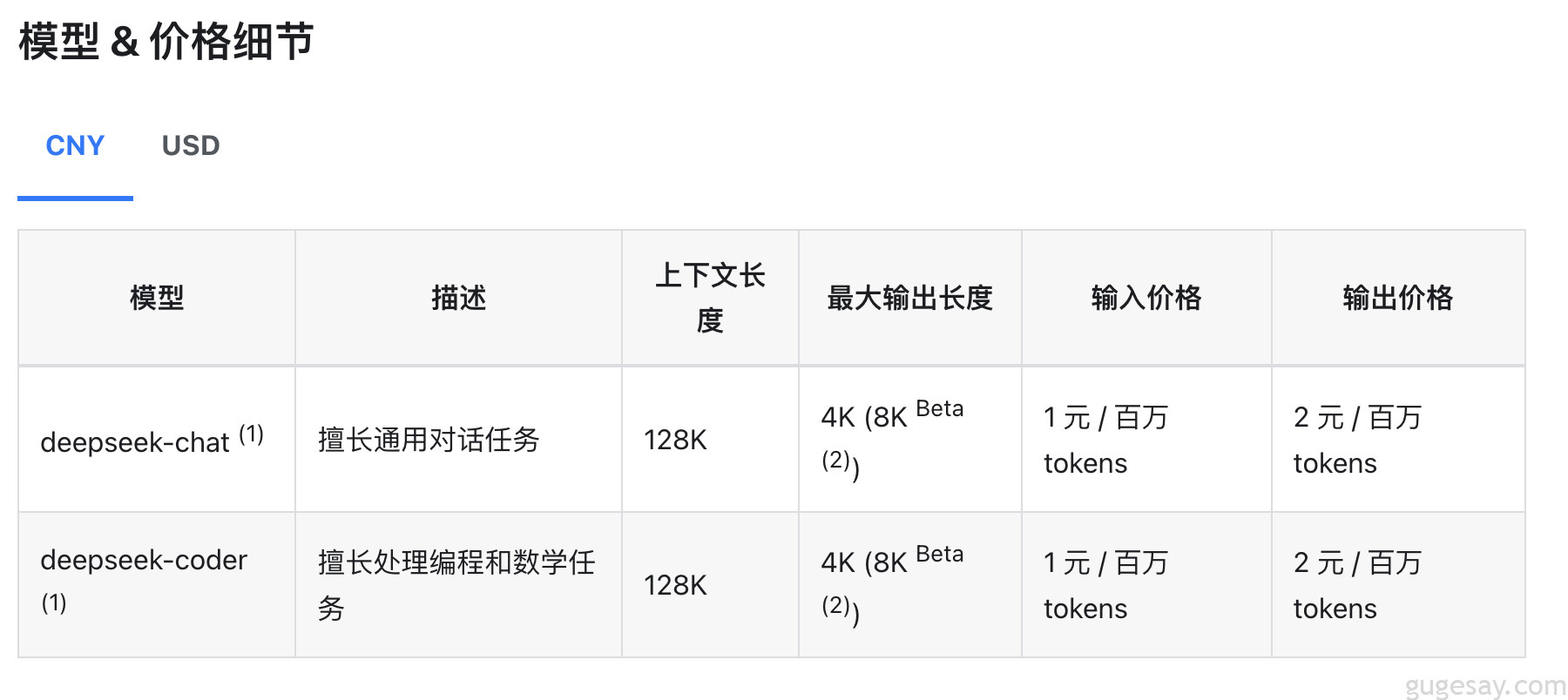
但如果我们本地能够部署大模型,那就不用花上一分钱就能畅享使用了~
本地部署API设置参考如下:
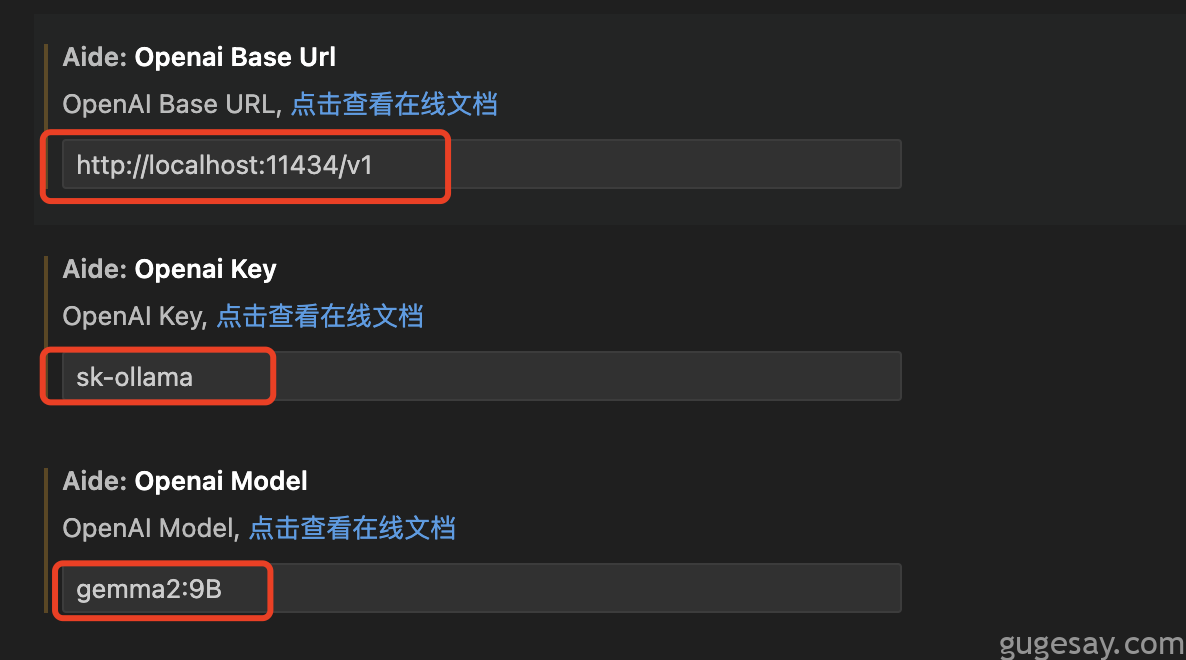
URL填写:http://localhost:11434/v1
KEY随便填写:sk-随便写
Model选择:使用哪个模型,就填写哪个,我这里是gemma2:9B
希望本文能对你有所帮助,如果你有更好的模型推荐,尤其是网络安全相关的模型,也欢迎在下方评论区或星球与我交流。
另一款基于AI的VScode插件教程:https://gugesay.com/archives/2221