



“纸上得来终觉浅,绝知此事要躬行。”——陆游《冬夜读书示子聿》
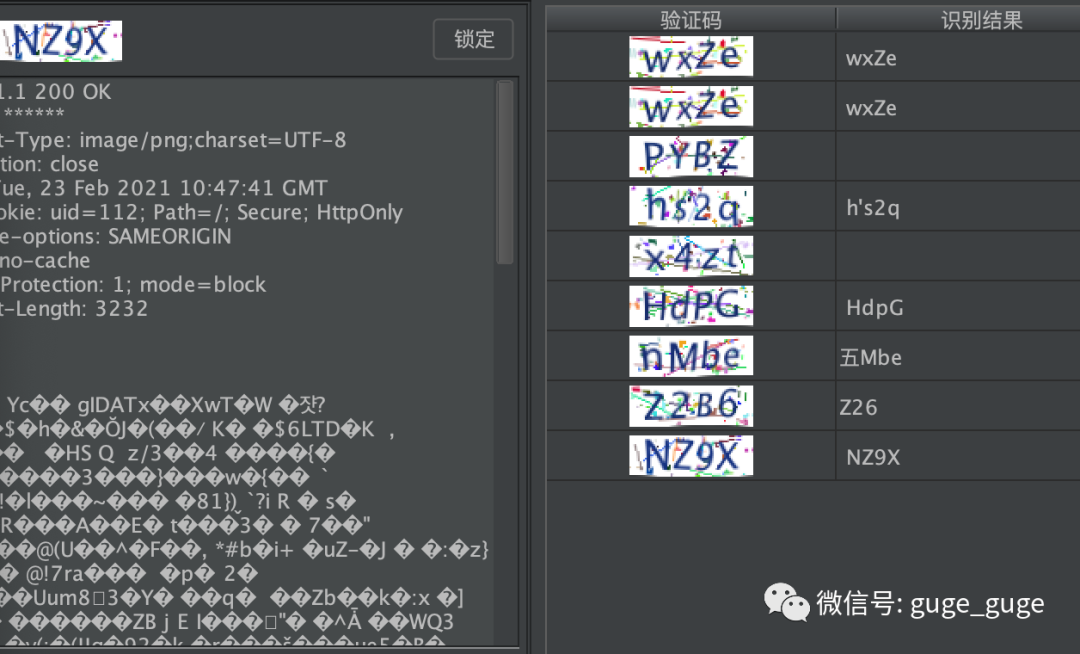
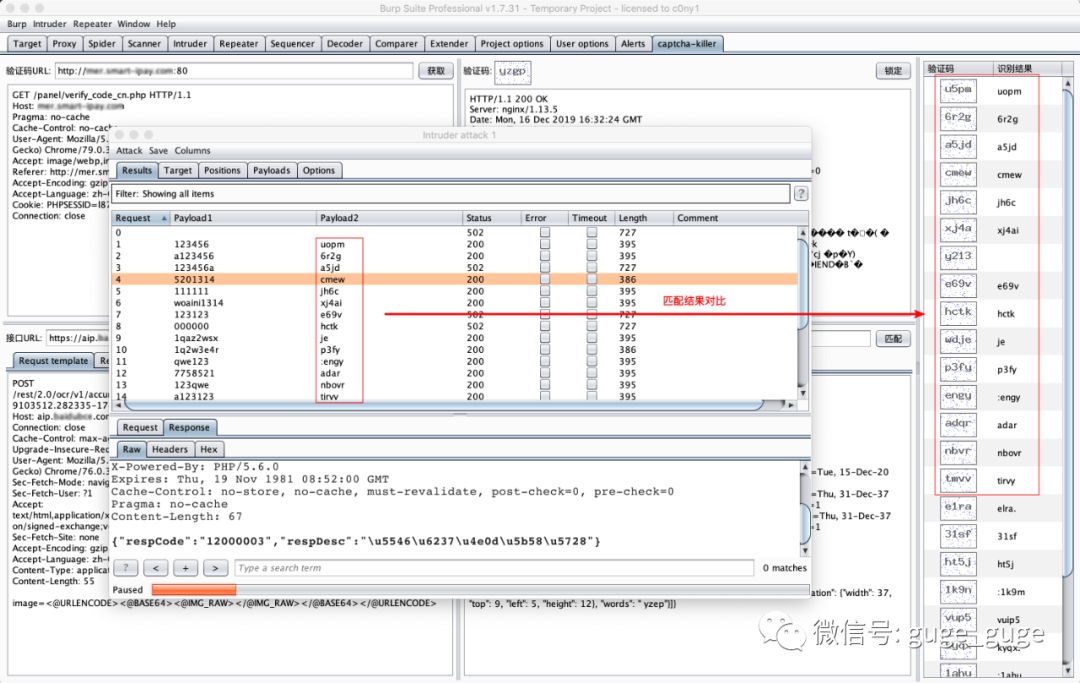
最近骨哥研究BurpSuite(以下简称“BP”)各类插件有点入迷,说来惭愧,之前骨哥也学着写过BP插件。然后发现了Captcha-Killer这个插件,于是想尝试看看验证码自动识别的效果,注册并开通了百度AI的“通用文字识别”API,使用后发现对于验证码的识别效果比较差,对于一些‘噪音’比较大的验证码识别率简直惨不忍睹,如下图:
于是就想着自己搞个开源的AI训练会不会好一些呢,在说这个之前,还是先简单讲一下Captcha-Killer这个插件的安装和使用吧。
0x00,Captcha-Killer下载与安装
下载地址:
https://github.com/c0ny1/captcha-killer/releases
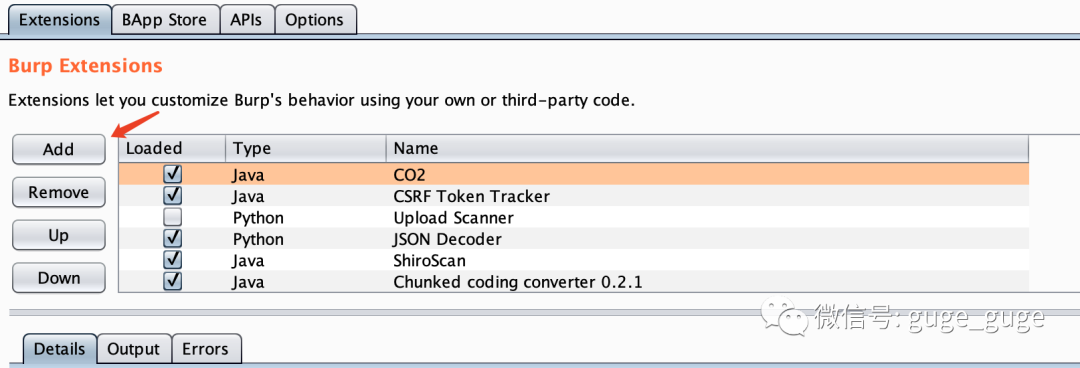
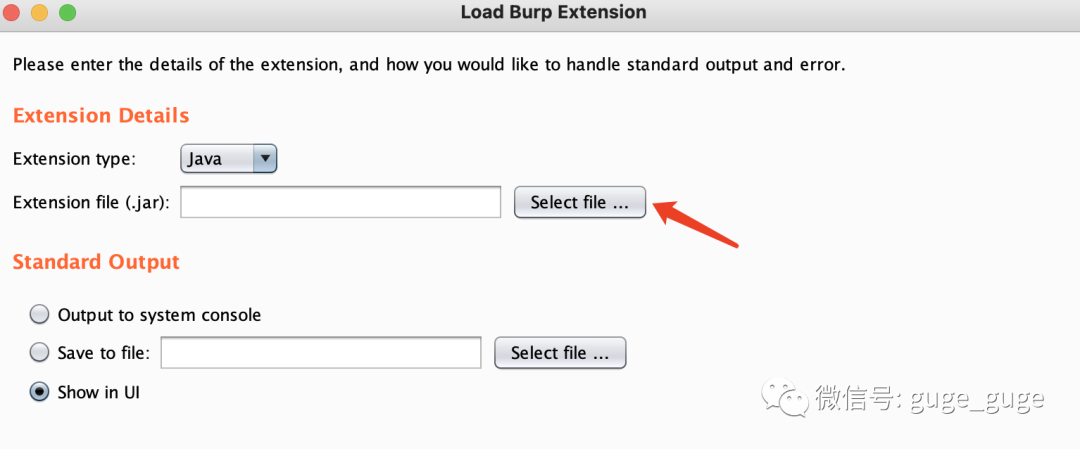
将jar包下载到本地,然后打开你的BP,找到Extender,点“Add”,选择刚刚下载好的jar包即可。
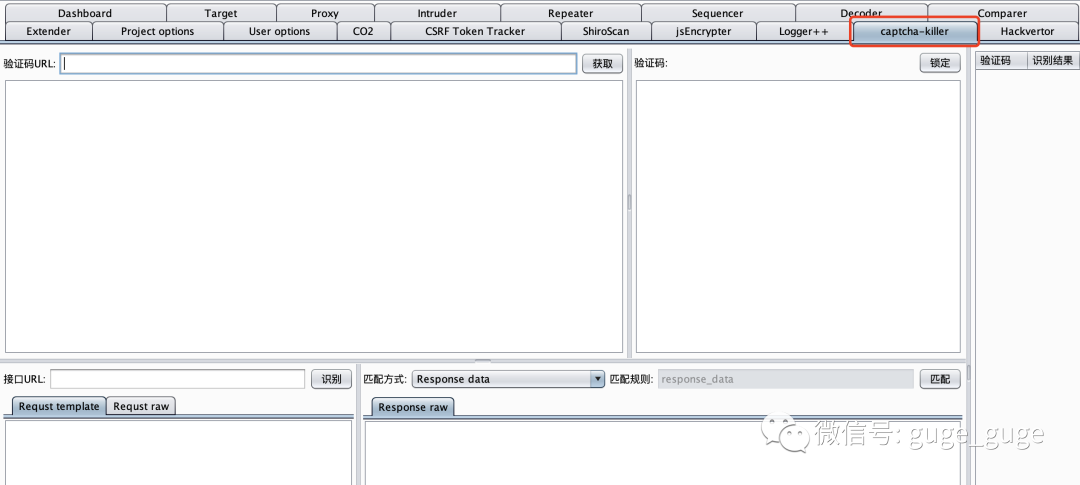
然后就可以在你的BP界面中看到多出的Captcha-Killer插件了:
0x01,Captcha-Killer使用及百度AI调用
具体使用方法,插件的作者c0ny大神在他的博文中有详细的介绍:
https://gv7.me/articles/2019/burp-captcha-killer-usage/
我这里就再啰嗦两句说一下如何调用百度API的方法(部分图片来自C0ny博文图片):
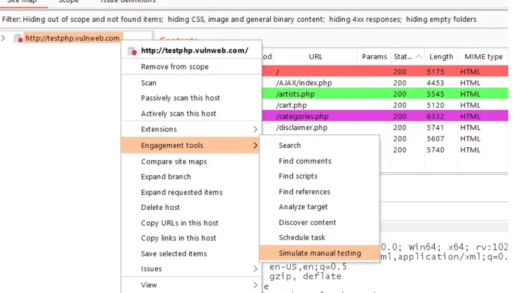
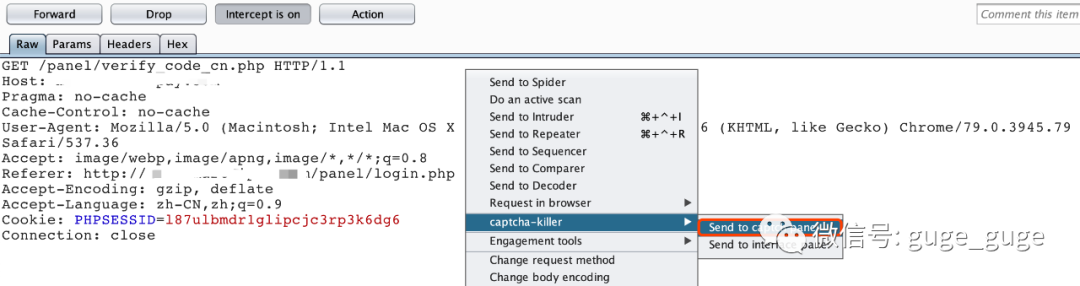
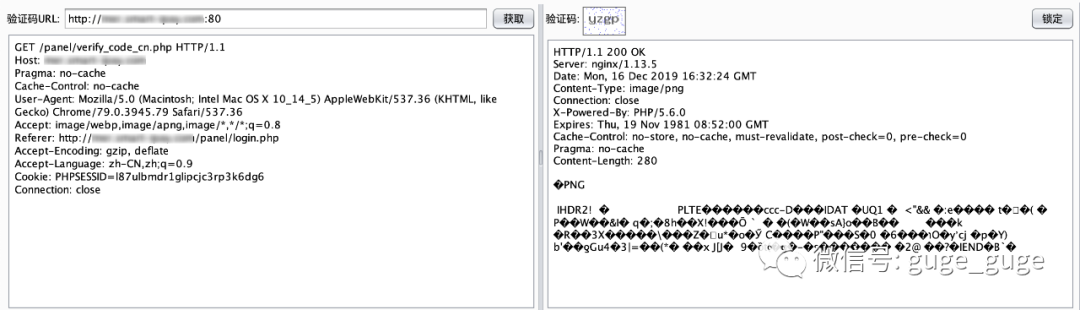
首先是用BP抓包时找到验证码的URL,然后在该URL上点击右键,直接发送到Captcha-Killer插件:
然后切到Captcha-Killer界面,点击获取按钮,如果右侧的验证码窗口成功出现了验证码图片,就表示成功获取到了:
而后在下方接口的窗口处点击右键,选择“模版库-baidu OCR”:
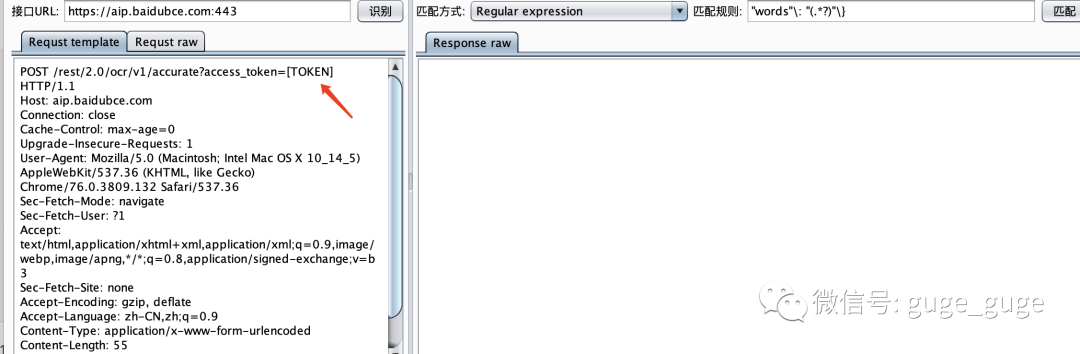
将上图中的TOKEN写入你申请下来的百度API的token即可,如果配置正确的话,就会像我第一张图中的样子,利用百度API实现文字识别了。
0x02,Captcha-Killer实现爆破
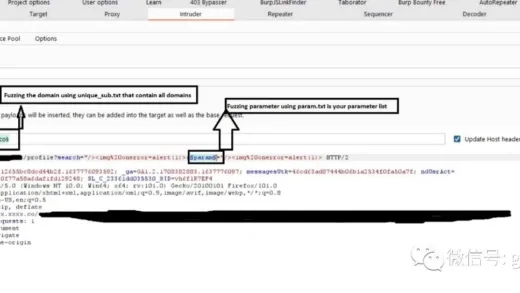
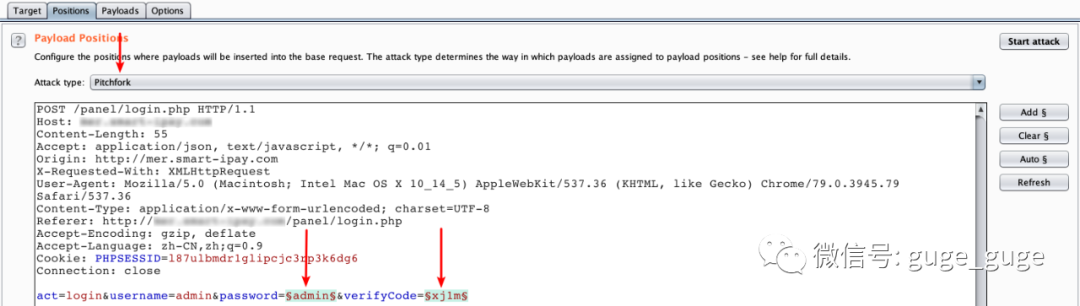
将登录时的数据抓包发送到BP的intruder窗口,在Positions窗口选择“Pitfork”模式,然后将密码和验证码设置为爆破参数:
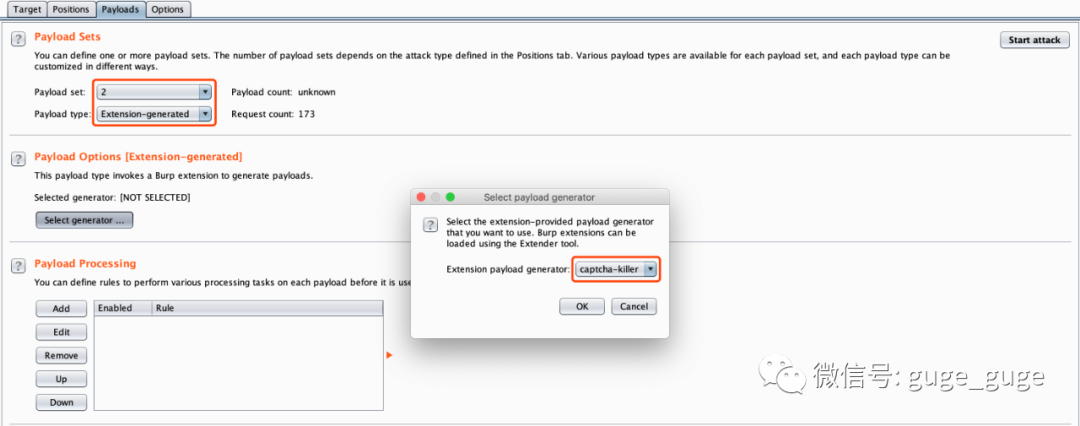
然后在“Payloads”窗口,payload set选择验证码参数,payload type则选择“Extensions-generated”,然后在弹出的窗口中选择Captcha-Killer插件,点击OK:
最后就是Attack,等待爆破结果了。
0x03,cnn_captcha安装和使用
关于cnn_captcha:
use CNN recognize captcha by tensorflow. 本项目针对字符型图片验证码,使用tensorflow实现卷积神经网络,进行验证码识别。项目封装了比较通用的校验、训练、验证、识别、API模块,极大的减少了识别字符型验证码花费的时间和精力。项目已经帮助很多同学高效完成了验证码识别任务。 如果你在使用过程中出现了bug和做了良好的改进,欢迎提出issue和PR,作者会尽快回复,希望能和你共同完善项目。
项目地址:
cat
将其git clone至本地,然后安装:
pip3 install -r requirments.txt -i http://mirrors.aliyun.com/pypi/simple/骨哥是在自己的云服务器上安装的,系统是Ubuntu16.04,Python3.6,pip3**要升级到20或以上才可以**。
如果是个人台式机且有独立显卡(最好是N卡)的话,可以在requirments.txt文件中,将tensorflow改为tensorflow-gpu==1.15.3
骨哥在自己台式机的Windows上安装tensorflow时遇到各种报错,查询后得知,要安装CUDA等工具,于是作罢,继续在云服务器上跑吧,安装成功后,就可以创建训练集进行训练了。
0x04,创建训练集
生成训练集的配置文件为conf/captcha_config.json,可进行修改生成的训练集数量,默认是20000,修改完成后,运行以下命令:
python3 gen_sample_by_captcha.py即可生成大量的训练集了。
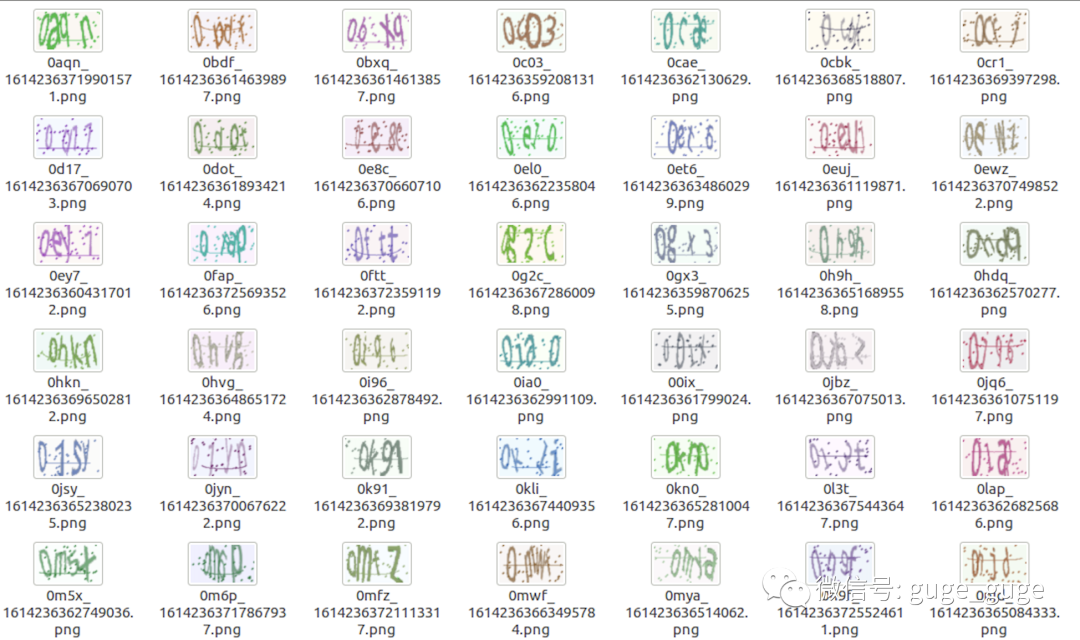
使用项目默认的验证码生成是下面这样的:
可在conf/sample_config.json中修改进行个性化训练:
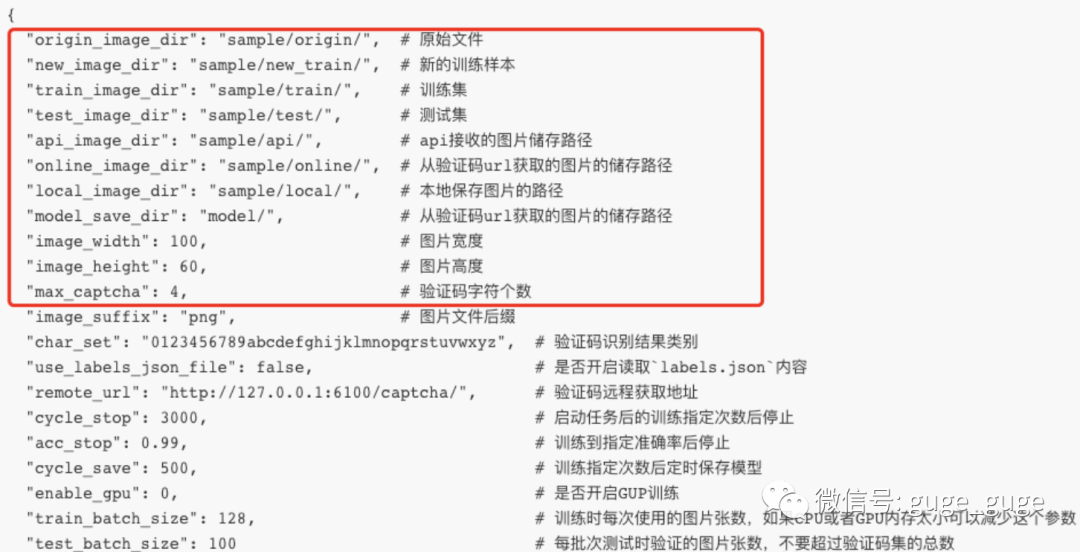
0x05,创建项目,开始训练吧
根据上面配置文件中要求,我们在sample目录下创建origin、train、test三个目录,然后执行如下命令:
python3 verify_and_split_data.py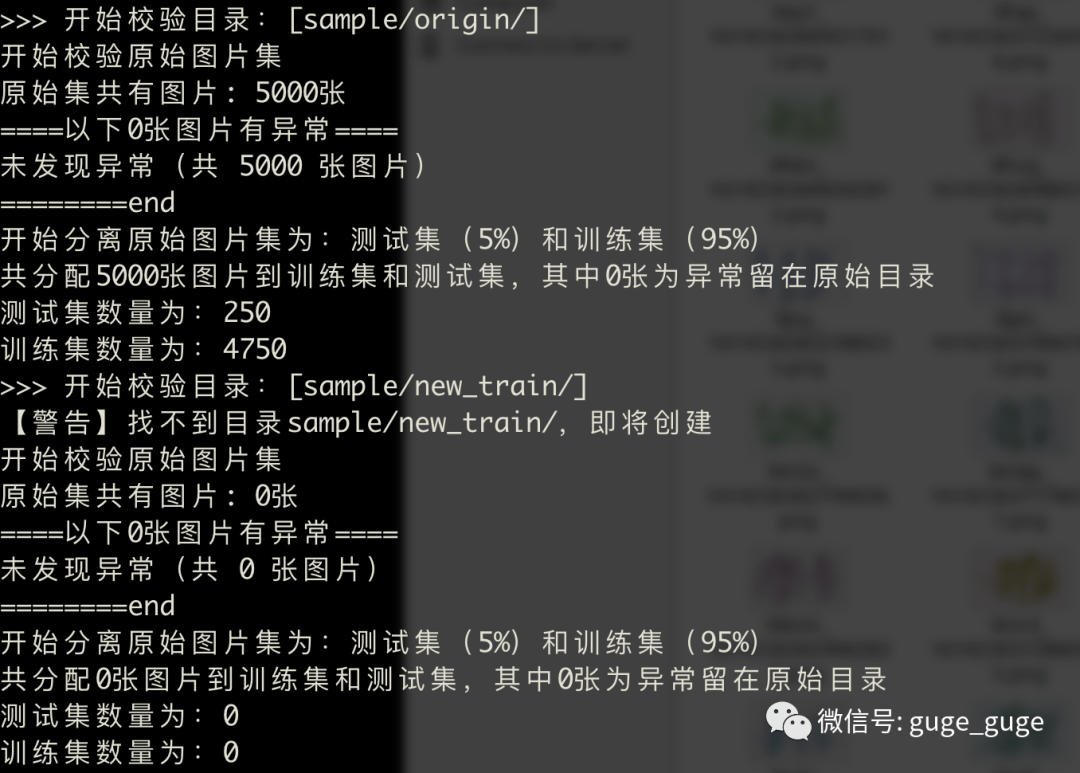
此时查看sample目录,发现origin文件夹已被清空,就表示OK了,那么运行下面的命令,就可以开始训练了:
python3 train_model.py骨哥在这步运行时报错
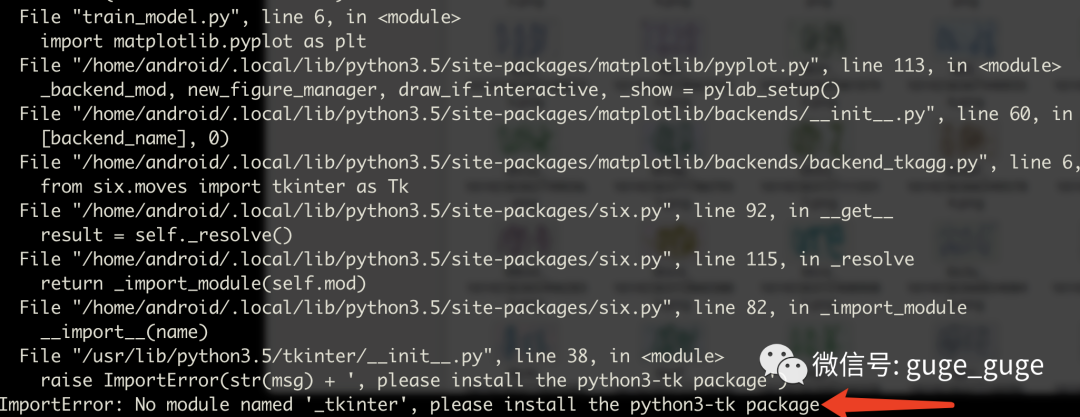
安装python3-tk库即可。
sudo apt-get install python3.6-tk然后就是耐心等待了,由于骨哥使用的CPU进行机器训练,时间消耗上比较久,如果是GPU的话,应该会快很多:
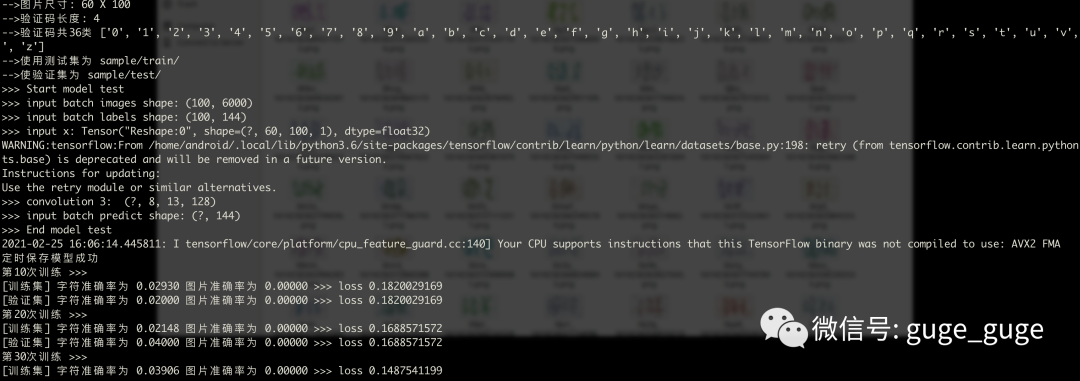
骨哥这边训练到4200次的时候,图片准确率达到100%,但字符准确率大概只有30%左右的样子,毕竟验证码中的字符样式比较复杂 ,如果验证码不是那么复杂的话,应该很快可以双双100%准确率。
,如果验证码不是那么复杂的话,应该很快可以双双100%准确率。

0x06,与**Captcha-Killer实现配合**
首先需要在webserver_recognize_api.py 文件中增加一个方法,以接受图片base64编码,用来配合Captcha-Killer,代码如下:
@app.route('/base64', methods=['POST']) #接受base64 图片返回识别结果 json格式
def up_imageBase64():
if request.method == 'POST' and request.form['image_file']:
timec = str(time.time()).replace(".", "")
file = request.form['image_file']#file = request.files.get('image_file')
#print(file)
img = base64.b64decode(file) #获取base64 转成图片
#img = file.read()
img = BytesIO(img)
img = Image.open(img, mode="r")
# username = request.form.get("name")
print("接收图片尺寸: {}".format(img.size))
img_size=img.resize((image_width,image_height),Image.ANTIALIAS) # 转化为100* 43大小
print("接收图片尺寸2: {}".format(img.size))
s = time.time()
value = R.rec_image(img_size)
e = time.time()
print("识别结果: {}".format(value))
# 保存图片
print("保存图片:{}{}_{}.{}".format(api_image_dir, value, timec, image_suffix))
file_name = "{}_{}.{}".format(value, timec, image_suffix)
file_path = os.path.join(api_image_dir + file_name)
img.save(file_path)
result = {
'time': timec, # 时间戳
'value': value, # 预测的结果
'speed_time(ms)': int((e - s) * 1000) # 识别耗费的时间
}
img.close()
return jsonify(result)
else:
content = json.dumps({"error_code": "1001"})
resp = response_headers(content)
return resp然后启动webserver
python3 webserver_recognize_api.py接口URL为:http://127.0.0.1:5000/base64
然后在Captcha-Killer插件中,指定使用cnn_captcha接口模版即可。
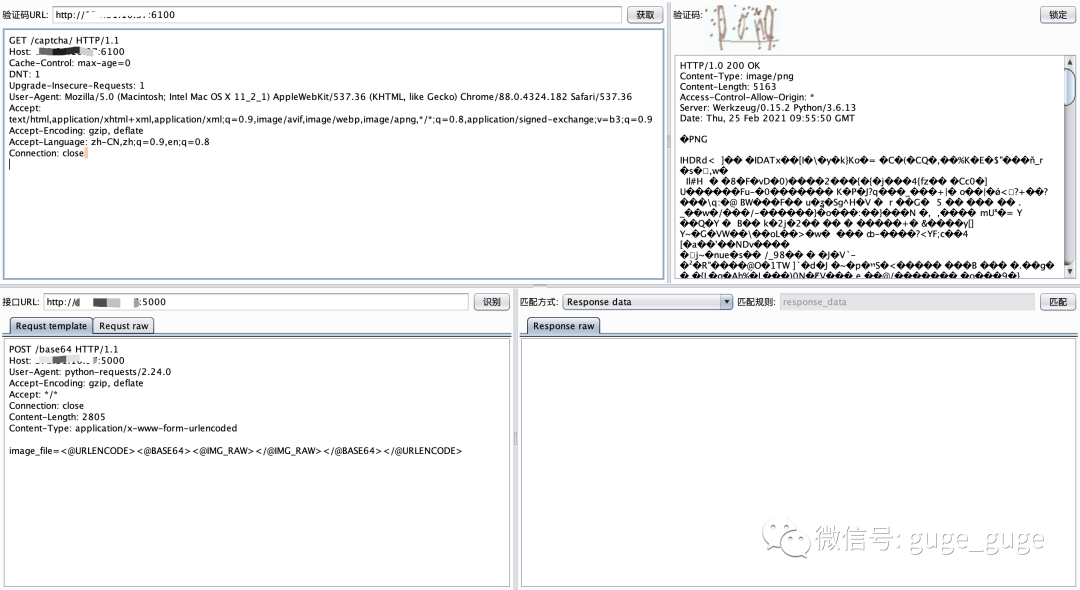
如果网站没有登录错误限制的话,基本就是愉快的爆破过程了~
0x07,后记
验证码的类型多种多样,所以要针对不同类型的验证码编写生成器,从而进行训练,这样才能有针对性的去实现自动化验证+爆破攻击。

加油吧,骚年,骨哥最近搞玩意搞得有点头秃,不过收获多多,祝各位童鞋一切顺利,挖洞多多~
0x08,参考资料
https://github.com/c0ny1/captcha-killer
https://zhuanlan.zhihu.com/p/240399663
https://cloud.tencent.com/developer/article/1734290
“原创不易,感谢分享!”