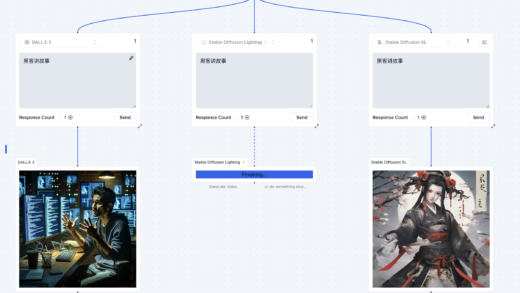




先说结论,B站出的这个开源语音大模型比阿里的RosyVoice效果要好很多,基本属于“天壤之别”了。
安装git-lfs
brew install git-lfs
安装项目
git lfs install
git clone https://github.com/index-tts/index-tts.git && cd index-tts
git lfs pull # 下载大文件安装uv
uv sync --all-extras --default-index "https://mirrors.aliyun.com/pypi/simple"这里会遇到“indextts[deepspeed] (v2.0.0) depends on deepspeed”错误,由于deepspeed不兼容macOS,故只能使用:
uv sync --extra webui
下载模型
uv tool install "modelscope"
modelscope download --model IndexTeam/IndexTTS-2 --local_dir checkpoints遇到pyenv: version `3.10′ is not installed错误。
直接pyenv安装3.10环境再下载模型即可。
pyenv install 3.10.13
modelscope download --model IndexTeam/IndexTTS-2 --local_dir checkpoints
运行
uv run webui.py
首次执行非常慢,需要等待下载基础模型。
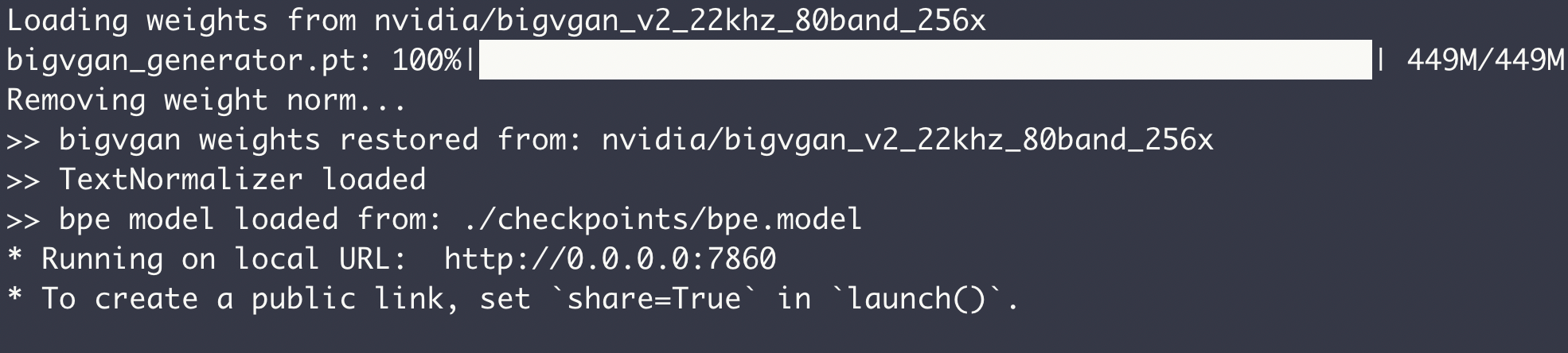
然后浏览器访问:http://127.0.0.1:7860 就OK了。
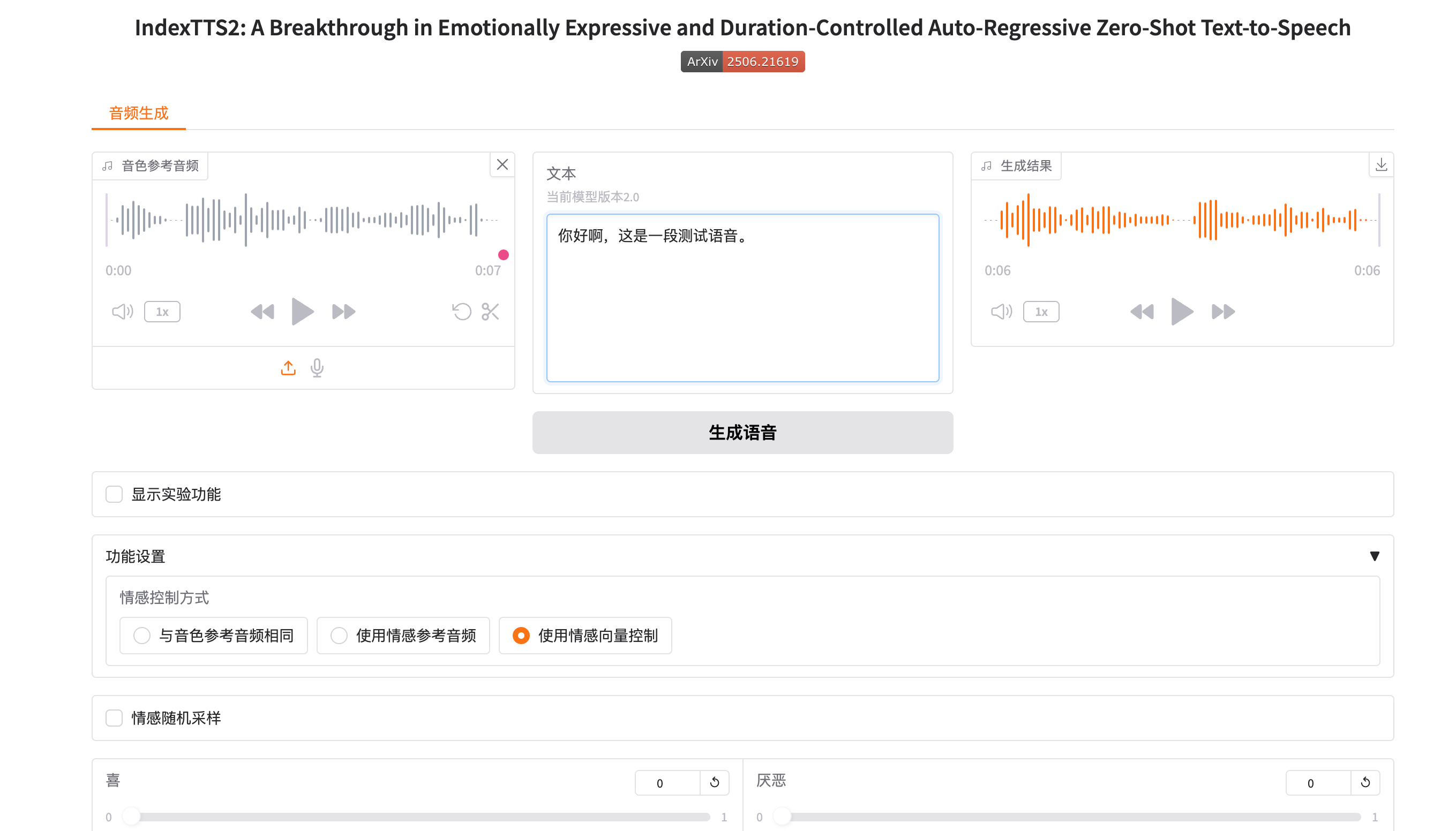
克隆并生成一段6秒的语音,大概耗时50秒。