




按照官方说明,一步步来。
下载及安装:
git clone --recursive https://github.com/FunAudioLLM/CosyVoice.git
cd CosyVoice
git submodule update --init --recursiveConda环境:
conda create -n cosyvoice -y python=3.10
conda activate cosyvoice
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com模型下载:
git lfs 安装:
> brew install git-lfs
> git lfs install# git模型下载,请确保已安装git lfs
mkdir -p pretrained_models
git clone https://www.modelscope.cn/iic/CosyVoice2-0.5B.git pretrained_models/CosyVoice2-0.5B
git clone https://www.modelscope.cn/iic/CosyVoice-300M.git pretrained_models/CosyVoice-300M
git clone https://www.modelscope.cn/iic/CosyVoice-300M-SFT.git pretrained_models/CosyVoice-300M-SFT
git clone https://www.modelscope.cn/iic/CosyVoice-300M-Instruct.git pretrained_models/CosyVoice-300M-Instruct
git clone https://www.modelscope.cn/iic/CosyVoice-ttsfrd.git pretrained_models/CosyVoice-ttsfrd模型下载比较慢,体量也比较大,耐心等待下载完成。
运行Webui:
python3 webui.py --port 50000 --model_dir pretrained_models/CosyVoice-300M-Instruct使用其它模型的话,Webui中预训练音色不显示:
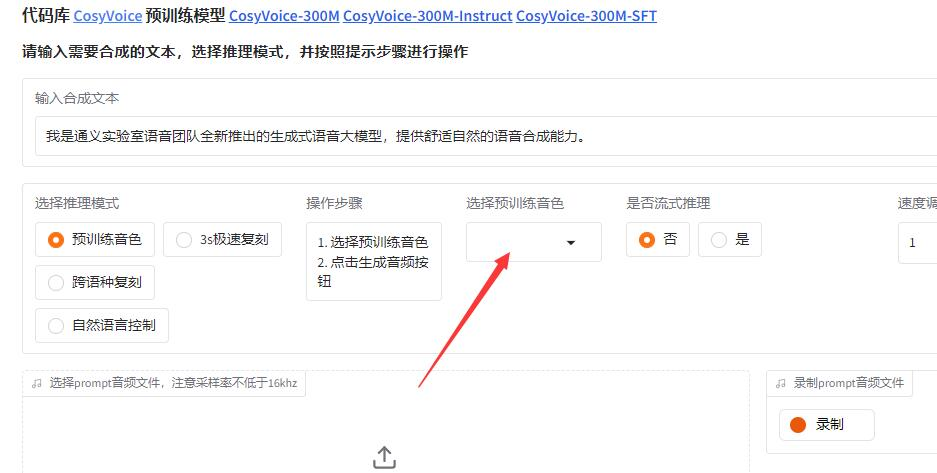
使用issue中的临时解决办法:
import sys
import gradio as gr
sys.path.append('third_party/Matcha-TTS')
from cosyvoice.cli.cosyvoice import CosyVoice2
from cosyvoice.utils.file_utils import load_wav
import torchaudio
import torch
cosyvoice = CosyVoice2('pretrained_models/CosyVoice2-0.5B', load_jit=False, load_trt=False, fp16=False)
def generate_audio(audio_path, tts_text, instruct_text):
if not audio_path or not tts_text or not instruct_text:
return None
prompt_speech = load_wav(audio_path, 16000)
# 生成音频
results = []
for i, j in enumerate(cosyvoice.inference_instruct2(
tts_text,
instruct_text,
prompt_speech,
stream=False
)):
output_path = f"output_{i}.wav"
torchaudio.save(output_path, j['tts_speech'], cosyvoice.sample_rate)
results.append(output_path)
if not results:
return None
# 拼接所有音频
waveforms = []
for path in results:
waveform, sr = torchaudio.load(path)
waveforms.append(waveform)
concatenated = torch.cat(waveforms, dim=1)
output_path = "output_combined.wav"
torchaudio.save(output_path, concatenated, cosyvoice.sample_rate)
return output_path
with gr.Blocks(title="CosyVoice TTS") as app:
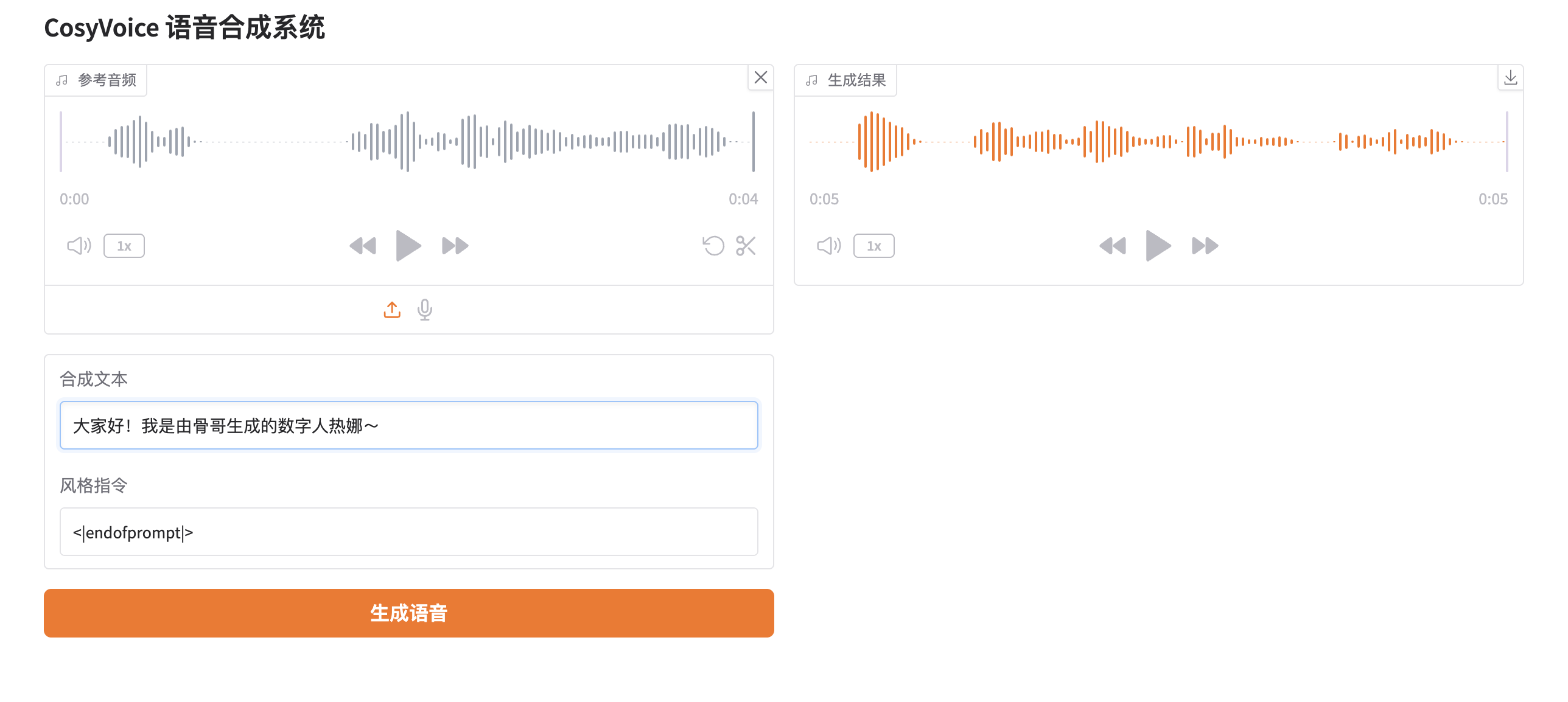
gr.Markdown("## CosyVoice 语音合成系统")
with gr.Row():
with gr.Column():
ref_audio = gr.Audio(label="参考音频", type="filepath")
tts_text = gr.Textbox(label="合成文本", placeholder="输入要合成的文本...")
instruct_text = gr.Textbox(label="风格指令", placeholder="输入语音风格指令...")
generate_btn = gr.Button("生成语音", variant="primary")
with gr.Column():
audio_output = gr.Audio(label="生成结果", interactive=False)
generate_btn.click(
fn=generate_audio,
inputs=[ref_audio, tts_text, instruct_text],
outputs=audio_output
)
if __name__ == "__main__":
app.launch(server_name="0.0.0.0", server_port=7860, share=False)然后运行:
> python3 web.py --port 50000 --model_dir pretrained_models/CosyVoice2-0.5B然后需要在“风格指令处”输入<|endofprompt|>,就可以使用CosyVoice2的预训练模型了。