







作者:Nick Kossolapov · 2026年4月
作者作为一名软件工程师已有超过8年的工作经验,但他坦言自己从未真正理解计算机是如何工作的。因此,他打算尝试通过模拟一台计算机来学习其工作原理。他向Ben Eater致歉,表示暂时还不打算动手造一台真机。
作者童年时曾花费数百小时捕捉宝可梦,所以Game Boy成为了一个完美的候选对象:它是真实的硬件,范围相对简单,并且与作者有强烈的情感联系。
他没有直接开始,而是首先完成了 《从与非门到俄罗斯方块》 课程。这门课程非常棒,让他真正理解了计算机的基础知识,例如寄存器、内存和算术逻辑单元(ALU)。为了适应构建模拟器,他还用F#构建了一个CHIP-8模拟器:Fip-8。
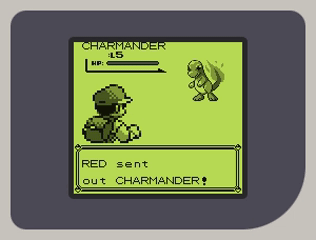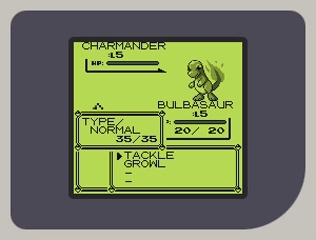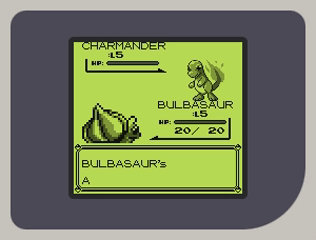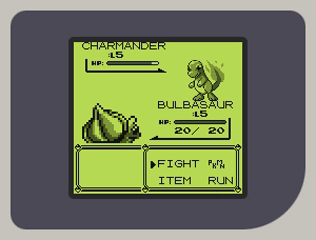
几个月后,在许多个告诉自己只工作一两个小时却熬到凌晨2点才睡的夜晚过后,他拥有了一个可工作的Game Boy模拟器:Fame Boy。它功能完整,带有声音支持,可以在桌面和网页上运行。
工作原理
作者希望模拟器能在桌面和网页上工作,因此他专注于在模拟器核心与任何运行它的前端之间建立一个简单的接口。
前端和核心之间的接口本质上只是两个数组和两个函数:
framebuffer– 一个160×144的数组,存储像素的灰度等级(白、浅灰、深灰、黑)。audiobuffer– 一个采样率为32768 Hz的环形音频缓冲区,带有读和写指针。stepEmulator()– 一个执行一条CPU指令并返回所用周期数的函数。getJoypadState(state)– 一个供前端向模拟器传递手柄状态的回调函数,通常每帧调用一次。

他尝试以类似于Game Boy实际硬件的方式来设计Fame Boy。
模拟器的 CPU 模块,就像Game Boy中真实的夏普LR35902芯片一样,除了内存映射(以及仅用于中断信号的I/O控制器)之外,对其他硬件一无所知。这也是他代码库中最具有F#风格的部分,大量采用了函数式领域建模。
Memory.fs 文件保存了Game Boy中使用的大部分RAM,并充当CPU、I/O控制器和卡带之间的内存映射和总线。为了性能考虑,它还与PPU(图像处理单元)共享对相同VRAM(显存)和OAM RAM(精灵属性内存)数组的引用。
IoController.fs 文件是在作者发现向 Memory.fs 添加了太多逻辑后出现的。虽然Game Boy硬件中并不存在一个单一的I/O控制器,但通过它来处理所有硬件寄存器,简化了各个组件的接口并增加了安全性。
Emulator.fs 文件中的 stepper 函数是将整个模拟器粘合在一起的胶水,它组合了所有组件的单独步进函数:
let stepper () =
// 执行一条指令
// 每条指令使用不同数量的周期
let mCycles = stepCpu cpu io
for _ in 1..mCycles do
stepTimers timer io
stepSerial serial io
// APU技术上是按4倍CPU周期运行的,但可以批量处理
stepApu apu
let tCycles = mCycles * 4
// PPU运行在4倍CPU周期下。APU也应该在这里
for _ in 1..tCycles do
stepPpu ppu
// 返回所用的周期数,以便前端以正确的速度运行模拟器
mCycles 尽管真实的硬件组件都基于一个中央主振荡器并行运行,但作者的模拟器是单线程的,因此组件必须按顺序运行。stepper 函数集中了执行过程,并确保所有组件同步。
最后,为了让模拟器可玩,它需要以正确的每秒周期数运行,大约每60帧需要17500个CPU周期。当开启声音时,前端使用音频采样率来驱动模拟器;当静音时,则使用帧率来驱动。这一点稍后会详细说明。
模拟CPU,以及F#的选择
首先,作者想向函数式编程纯粹主义者致歉。虽然 他的CHIP-8模拟器 是完全纯粹的(没有 mutable 成员,所有数组都被复制以避免副作用),但Fame Boy自由地使用了可变性。Game Boy的运行速度远快于CHIP-8,每秒复制16KB以上的内存一百万次似乎并不是明智之举。
那么,为什么使用F#来构建Fame Boy?首先,作者认为其广泛的类型系统非常适合对CPU指令进行建模。其次,更重要的是,他非常喜欢F#。他曾在上一家公司主要使用F#工作,因此总是找机会继续使用它。
领域建模
作为一个例子来说明为什么作者认为CPU建模在F#中很有效,在实现CPU时他参考了 Gekkio的完整技术参考文档。他像参考文档中那样对指令进行了分组,最终在 Instructions.fs 文件中得到了类似下面的结构:
type LoadInstr =
| Load8Immediate of uint8
| Load8Direct of Register
| Load8Indirect
// ... 其他加载指令
type ArithmeticInstr =
| IncrementDirect of uint8
| IncrementIndirect of Register
// ... 其他算术指令不仅仅是加载指令,许多其他指令也共享类似的概念,例如指令操作数的位置:
- 从指令后紧邻的内存中读取字节值 (
immediate), - 读/写一个CPU寄存器 (
direct), - 读/写由HL CPU寄存器指定的内存位置 (
indirect)。
尽管这是一个很小的领域,大多数Game Boy开发者基本上都熟知操作码/指令,但作者感觉可以将其整理得更简洁。下面的代码展示了提取位置概念的过程。为了便于不熟悉F#可区分联合的读者阅读,代码使用了与源码不同的名称和顺序来使加载指令更易读。
type To =
| Direct of Register
| Indirect
type From =
| Immediate of uint8
| Direct of Register
| Indirect
type LoadInstr =
| Load of From * To // 这些形成一个元组,类似于C#中的Load<From, To>
// ... 其他指令这有助于将CPU指令从512个操作码减少到仅仅58个指令。像这样泛化领域存在允许非法状态的风险,但使用一个好的类型系统可以避免这一点。
例如,如果他使用一个位置类型 Loc 来代替 From 和 To 类型,那么 Load(Loc.Direct D, Loc.Immediate) 这样的指令(将一个寄存器存储到立即值中)将可以毫无警告地编译通过。Game Boy的硬件(其领域)不支持向立即值写入,因此该领域将包含一个非法状态。
通过使用F#类型系统正确地对领域建模,你可以得到一个保证:非法状态无法在你的系统中表达。你不需要单元测试,它根本就无法编译。因此,使用简化后的类型,Fame Boy仍然准确地捕捉到Game Boy CPU所支持的功能,仅此而已(有一个例外)。
现在,眼尖的Game Boy模拟器开发者可能会说:“嘿,Nick,那操作码0x76呢?”,而作者会回答“一个幺半群是函子范畴中的内函子”来显示他使用的是函数式编程语言,因此比他们更聪明。
开个玩笑,这是他为了简化CPU领域而决定做出的妥协。如果你查看操作码遵循的模式,0x76 将是 Load(From.Indirect, To.Indirect),或者将HL寄存器指定的内存地址中的8位值加载到HL地址指定的内存中。他的模拟器类型系统允许这样做,但该指令实际上在Game Boy上并不存在。从逻辑上讲,这是一个空操作(NOP),并不危险,并且在实践中是不可达的,因为操作码读取器将 0x76 解码为 HALT。但这是他自认为不错的领域模型中的一个明显瑕疵。
现在,你可以在大多数语言中做类似的事情,但如果你使用过函数式语言,就很难准确描述使用这些类型是多么流畅。在F#中使用 match 语句或选项类型(Options)之后,再回到 switch 语句会感觉笨拙且容易出错。作者建议任何没有使用过函数式编程语言的人都去尝试一下。
保持简单
由于本项目旨在学习计算机硬件,而非构建最好的模拟器,作者几乎从未深入查看过其他模拟器的代码。然而,在随意浏览 CAMLBOY 的源代码时,他发现了如下代码行:
set_flags ~h:false ~z:(!a = zero) ();他非常喜欢这种方式(可以按任意顺序传入任意数量的标志位)。由于它们只是方法的命名参数,性能开销很小。
但他无法创建完全一样的东西,因为F#由于其类型系统支持部分应用,避免了方法重载和默认参数。他最终采用了类似这样的方式:
cpu.setFlags [ Half, false; Zero, a = 0uy ]他一直对此不太满意,因为它需要一个数组和一个标志类型(例如 Half)。但他还是继续使用了,因为他想取得进展。在接近完成时,他花了很多时间回顾和重构旧代码,并试图改进 setFlags 函数。经过大量的思考和尝试其他方法后,他最终得到了这个(参见 Cpu/State.fs 第81行):
module Flags =
let inline setZ (v: bool) (f: uint8) =
if v then f ||| ZMask else f &&& ~~~ZMask
let inline setH (v: bool) (f: uint8) =
// ... 其他标志函数和定义
// 其他文件
cpu.Flags <-
cpu.Flags
|> setH false
|> setZ (a = 0uy)这些函数正是他想要的。它们可以轻松组合和测试,只是简单的纯函数。堪称完美。
之前的函数需要将值提升到可区分联合类型并放入数组中,导致 setFlags 函数更加冗长。此外,由于这些函数是内联的且不需要任何堆分配,新函数实际上性能更高,使模拟器的FPS提高了约10%。
他认为那个简单的16行Flags模块可能是他写过的最喜欢的F#代码。
测试
最初,他只用这个函数和运行《俄罗斯方块》ROM来构建CPU:
match opcode with
| 0x00 -> Nop
| _ -> failwith "未实现的操作码"然后每次遇到异常时,他就实现该操作码对应的指令。他很快发现了这种方法的两点问题:循环变得有点乏味,需要在技术参考中随机导航,而不是专注于一组一组地实现指令;而且他无法确定自己是否正确实现了指令。修复这两个问题很简单:进行单元测试。
这正是AI真正派上用场的地方。为了改进学习效果,他想自己编写模拟器代码,但编写测试用例会很繁琐,而且他可能会有思维定势,错过一些重要的测试用例。因此,他使用了两个提示词,在其中包含了技术文档中的规范,并要求AI在不查看模拟器代码的情况下为这些规范编写测试。在AI工作时,他自己阅读规范,并实现逻辑直到测试通过:真正的测试驱动开发。AI甚至帮助他发现了已实现指令中的几个bug。
他确实定期审查和改进测试,但总体感觉这并没有减损他的学习,反而帮助他将精力集中在真正感兴趣的事情上。
超越CPU
PPU(图像处理单元)
Game Boy没有GPU,它有一个PPU,即图像处理单元(Picture Processing Unit)。尽管在他心中,它实际上代表像素处理单元(Pixel Processing Unit)。在处理像素上花费的时间比处理任何图像都要多。
这是让他在阅读其他制作Game Boy模拟器的人的博客时感到惊讶的部分。许多博客聚焦于CPU,而对于PPU往往只有几段话的描述。也许是因为他刚学完《从与非门到俄罗斯方块》并制作了CHIP-8模拟器,CPU感觉很自然,而PPU则需要更长的时间来理解。但既然他已经实现了它,就能明白原因了。这更多的是关于遵循将像素放在屏幕上所需的步骤,是机械性工作而非创造性设计。
在开始实现PPU时,他有点不知所措。因此,他没有试图一次性理解像素FIFO和完整的PPU流水线,而是决定直接从内存中读取图块和背景地图,解析数据,然后将其放在屏幕上(下图右侧部分)。他终于能看到他的CPU在工作了,并且得益于《俄罗斯方块》的简单性,他能看到 基本 像是一个真实的Game Boy游戏。第一次看到它时感觉棒极了。
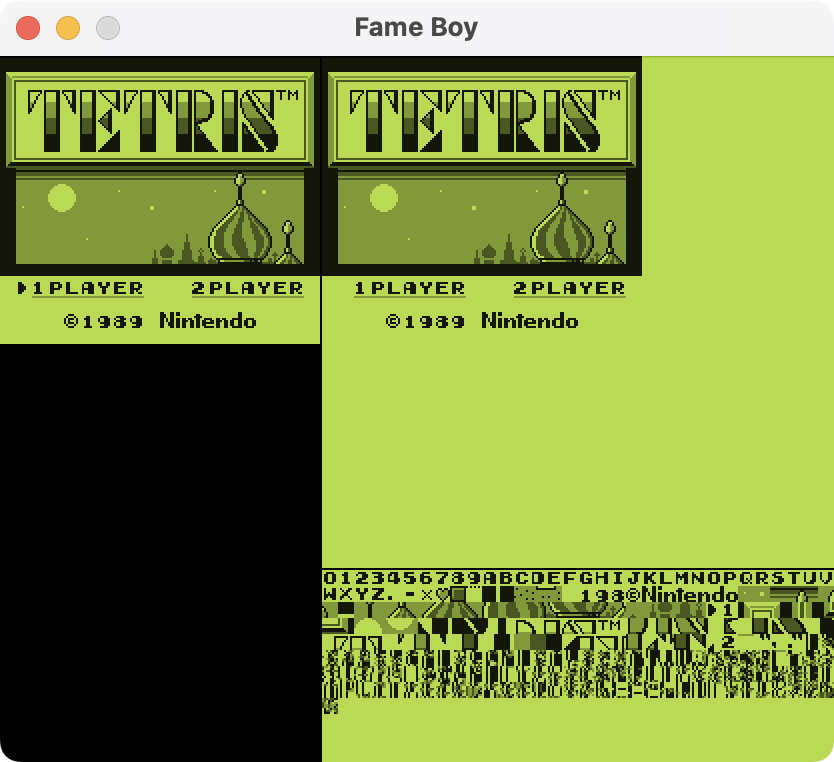
对于PPU来说,从图块和背景视图开始,回过头看是一个很好的起点。在过程的几乎每个阶段,从实现实际屏幕到调试精灵数据的烦人细节,这都帮助了他。
总的来说,他对PPU的结果感到满意,但其中可能存在他模拟器中最大的硬件不准确性。Game Boy使用FIFO队列像CRT显示器一样逐个像素地显示画面,但他的模拟器在该行的绘制周期开始时一次性渲染整个扫描线。这样做速度更快,代码也更简单,并且他想玩的游戏都能运行,所以他觉得没有必要改用像素队列。有些游戏的开发者将Game Boy硬件推到了极限并利用了像素队列的时序,那些游戏在Fame Boy上无法正常运行。但大多数游戏并没有那么激进地使用硬件,应该基本都能运行。
手柄
除了主要组件(PPU和APU)外,作者还想谈谈手柄。最初的实现非常顺利。它很直接,易于编写测试。
但在几乎任何重大重构之后,它总是会出错。手柄硬件寄存器是一个CPU和游戏都会读取和写入的寄存器,因此它们会以令人沮丧的有趣方式相互作用。
举个例子,在模拟器的早期阶段,他让CPU每个周期都将手柄状态写入寄存器。但这效率很低,人类不会每秒改变按钮一百万次,所以他改为每帧只更新一次。然后方向键就失效了。经过一些阅读,尽管他知道Game Boy硬件一次只允许读取一半的按钮,但他发现游戏几乎总是至少连续两次快速读取手柄寄存器,依赖于寄存器在这两次读取之间发生变化。游戏这样做是为了读取所有按钮的状态。但现在寄存器被缓存了且不变化,因此一半的按钮不起作用。真有趣。
最终,他改为让I/O控制器仅在CPU读取时才更新手柄寄存器,但他可能应该花些时间为其编写一个集成测试。感兴趣的读者可以查看 Pandocs中关于手柄的部分 以了解更多。
声音很难实现
当他完成并拥有一个可工作的模拟器后,他充实了仓库的README,并准备写这篇博客。但在摆弄网页版时,他觉得没有声音感觉有点空。于是他尝试添加APU,即音频处理单元(第一个错误)。他读了几篇博客,发现许多模拟器使用前端音频采样率来驱动模拟器,而不是帧率。这对他来说听起来是反过来的,于是他研究了动态采样率,并决定在帧率驱动模拟器的同时使用它(第二个错误)。
声音对他来说在概念上最具挑战性。他花了一段时间才理解不同的声音寄存器和声道是如何工作的。这正是AI作为老师真正闪耀的地方。他开始编码之前进行了大量的来回交流。但就像PPU一样,当他完成每个声道时,真的很有满足感。通过一次实现一个声道,帮助他理解了音乐实际上是如何形成的。听到《俄罗斯方块》的歌曲慢慢成型并逐渐丰富起来,确实让他脸上露出了笑容。
但并不是一切都很美好。CPU和PPU基本上就是“每帧执行X次操作”,并且你可以轻松计算X。但APU则完全不同,除了计算外,还有很多东西需要选择和调整。
唯一容易选择的是APU的采样率。实际的Game Boy APU是灵活的,因此模拟器可以使用任何他们想要的采样率。他选择了32768 Hz,因为这样下来每128个CPU周期产生一个采样(CPU主频1,048,576 Hz,1,048,576 / 32,768 = 128)。这样他的APU状态可以使用整数并保持完美同步。128也能被4整除,因此他可以将APU步骤批量处理,每次4步,永远不会错过与CPU指令的对齐。
但其他所有事情就更加棘手了。他不是一个声音工程师,因此只是改变值期望最好的结果。最糟糕的是,不仅每个前端都有自己的怪癖,每个平台也如此。他在PC上让声音工作得很好,但在MacBook上尝试时,听起来像瀑布一样。他修复了MacBook的问题后,PC端的桌面版突然因为竞态条件甚至无法运行。
在调整设置和失败几个小时后,他放弃了尝试用动态采样率来耍聪明,转而使用音频来驱动模拟器。这使得音频在所有设备间的可靠性大大提高了。
这绝对也是模拟器-前端接口中最具泄露性的部分,但这确实是因为音频需要精确同步以避免产生刺耳的声音。
驱动模拟器
为了解释音频驱动和帧驱动之间的区别,更多是关于理解人类的感知。
当你在听某个东西时,你知道那种“噗”的一声吗?那是音频信号中出现了缺失,导致扬声器因信号的突然变化而大量移动,产生了噗声。当视频卡顿时也会发生同样的事情,没有足够的数据及时传入,所以视频播放器必须跳过一两帧。只是现在它不是推动某个物理对象,所以对我们的感官不那么具有冒犯性。
现在回到驱动模拟器。在Fame Boy中,音频和视频是完美同步的,因为它的设计就是这样。但运行它的计算机具有独立的音频和视频,其中任何一个都可能偶尔落后。因此,当前端的音频和视频不同步时,它有两个调整选项可以尝试:
- 保持前端音频和模拟器音频同步,偶尔丢帧。
- 保持前端视频和模拟器帧同步,偶尔丢弃音频。
因此,你选择哪一个来“驱动”模拟器,同时仍然试图让另一个保持接近。使用帧率驱动相对直接。这是一个简化版本:
let mutable cycles = 0
while (runEmulator) do
cycles <- cycles + targetCyclesPerMs * lastFrameTime
while cycles > 0 do
let cyclesTaken = stepEmulator ()
cycles <- cycles - cyclesTaken
draw ppu.framebuffer声音则有点棘手,因为Raylib和Web Audio处理音频的方式不同。一般的流程是:
let tryQueueAudio apu stepEmulator =
if frontend.audioBuffer.hasSpace () then
while apu.writeHead - apu.readHead < samplesNeeded do
stepEmulator ()
frontend.audioBuffer.fill apu.audioBuffer
while (runEmulator) do
tryQueueAudio apu stepEmulator
draw ppu.framebuffer关键区别在于 stepEmulator 不再受 lastFrameTime 控制。相反,它由前端音频缓冲区的需求驱动。需要计算 samplesNeeded,以便调用正确次数的 stepEmulator 来匹配不同的采样率并产生60 FPS。
然而,前端的音频缓冲区只关心填满自己,因此它有时每帧调用 stepEmulator 的次数过多或过少,导致帧缓冲区不能及时更新。
实际上,你可以在网页前端尝试帧驱动版本,只需在URL中添加查询参数 ?frame-driven。它在视觉上应该更平滑,但偶有音频噗声。此外,即使是音频驱动的网页前端,在按下静音按钮后也会切换到帧驱动,因为那些噗声不会被听到。
作者承认,他对此的实现远非完美。最终,他发现音频噗声比帧卡顿留下更坏的印象,而让模拟器静音又感觉空洞,因此他决定在网页前端中默认使用音频驱动。音频是Fame Boy中少数几个作者不太满意的领域之一,并希望将来重新审视。
使用Fable将其推向网页
当作者让PPU基本工作并能在桌面屏幕上看到一些画面后,他很兴奋地尝试将Fame Boy移植到网页上。他查阅了 Fable 文档,安装了一个包,设置了主循环,添加了一些样式,在一两个小时内就准备运行了。他按下回车,然后看到了:

也许这个版本的《俄罗斯方块》设定在西伯利亚的冬天。
他尝试调试了一会儿,但没有花太多时间,而是转去尝试使用 Blazor 和 WebAssembly。这也同样容易启动和运行,而且这次确实有效。
但有一个问题,它几乎无法玩,大约只有8 FPS。他仍然不确定问题是什么。他不认为是Blazor本身的原因,.NET团队发布的性能指南他尝试遵循了,但最终没有帮助。调试也很痛苦,因此他不情愿地回到Fable,研究将代码转译成JavaScript可能出现的问题。
令他惊讶的是,Fable将转译后的JS文件直接放在源代码旁边,而且这些JS文件实际上相当可读。
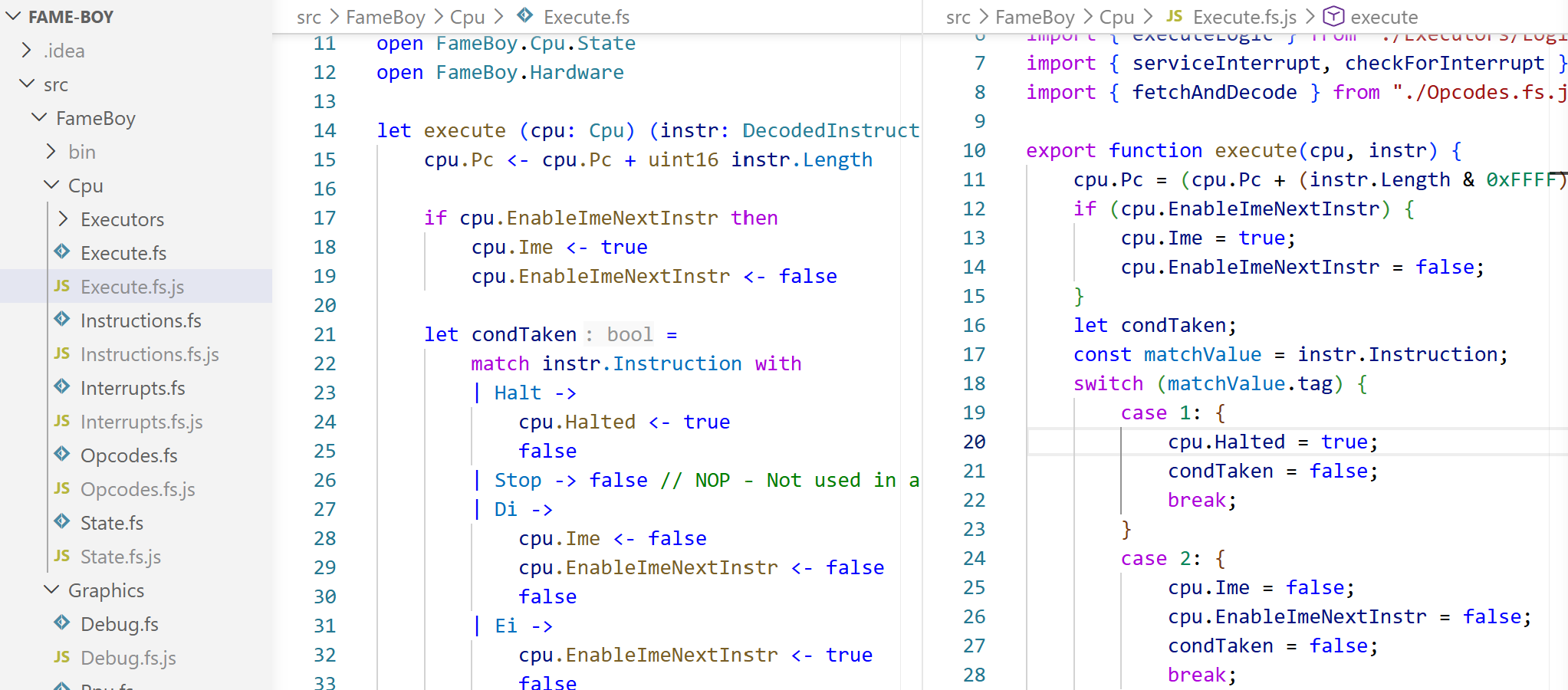
这使得理解新代码以及在浏览器开发工具中调试变得相当直接。在查看开发工具时,他注意到有些地方不太对劲。
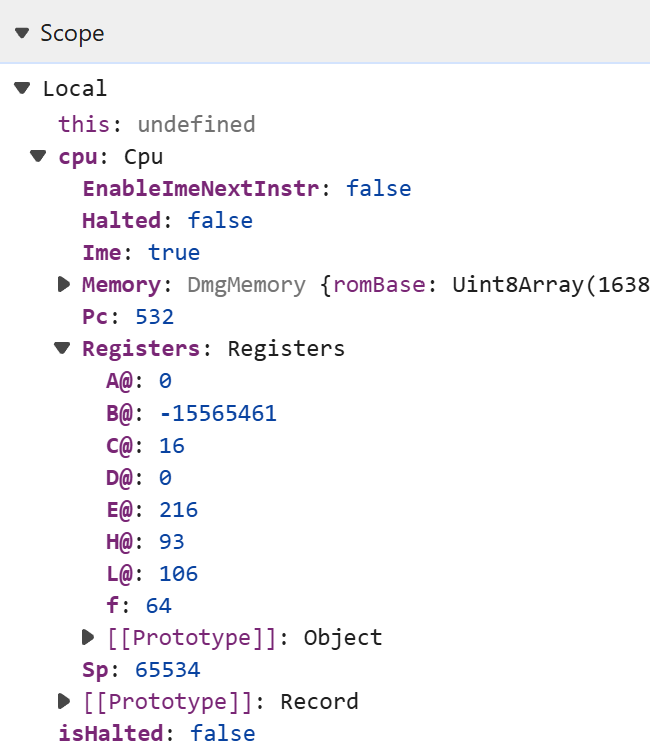
Fame Boy(以及Game Boy)中的CPU寄存器是8位无符号整数,范围在0-255。他不是专家,但他认为-15,565,461不是8位数。他查看了转译代码和Fable文档,发现了 这个说明:
(非标准)对于16位和8位整数的位操作使用底层JavaScript的32位位操作语义。结果不会像预期那样被截断,移位操作数也不会被屏蔽以适应数据类型。
这可以解释B寄存器的异常。通过查找代码中所有需要截断8位值的地方,他设法 找到了所有问题点,然后前端就完美工作了。并且由于它只是没有.NET运行时的JS代码,网页打包文件只有大约100 KB。
除了奇怪的uint8问题(大多数人应该不会遇到),他对Fable的体验相当愉快。它相当流畅,并且意味着所有源代码都保留在F#中。
尝试提升性能
当屏幕上开始显示画面后,他很好奇性能如何。他在控制台添加了一个简单的FPS日志。当时在调试模式下大约是55-60 FPS。不算好,也不算坏。他认为那是由于Raylib试图维持垂直同步。当他关闭垂直同步后,模拟器跳到了大约70 FPS,但有卡顿。他觉得以后总可以优化,于是决定继续推进PPU的开发。
随着添加更多功能,性能逐渐下降,最终达到45 FPS,关闭垂直同步也帮不上忙。“以后”来了,是时候优化了。他启动了JetBrains Rider的性能分析器,看到了这个:
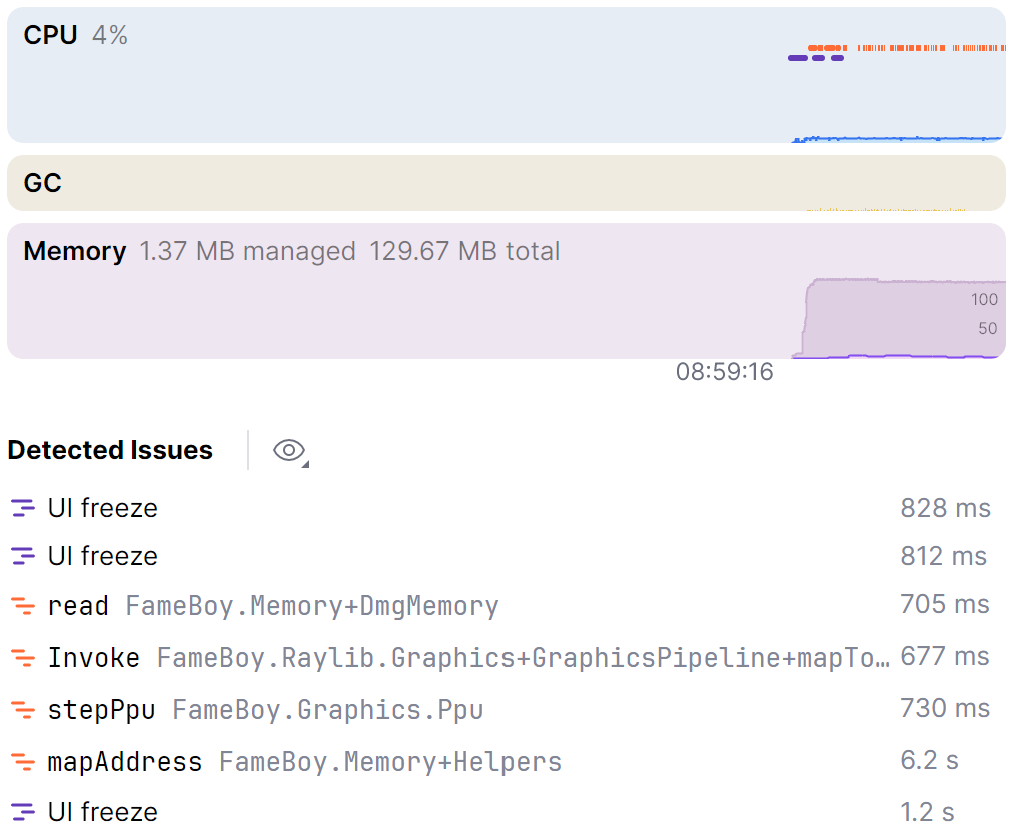
mapAddress 看起来非常可疑。几乎每个组件都会访问内存,但为什么它比其他部分高那么多?他深入查看了其他函数调用(如 stepPpu),发现所有组件在访问内存上花费的时间都比他预期的多。于是他查看了有问题的代码:
type MemoryRegion =
| RomBase of offset: int
// ... 其他情况
let mapAddress (addr: int) : MemoryRegion =
match addr with
| a when a < 0x4000 -> RomBase a
// ... 其他情况
type DmgMemory(arr: uint8 array) =
// romBase等的数组
member this.read address =
match mapAddress address with
| RomBase i -> romBase[i]
// ... 其他情况
member this.write address value =
match mapAddress address with
| RomBase _ -> ()
// ... 其他情况 当时他身上还带着CPU领域驱动开发的兴奋劲儿,试图将其扩展到内存。这意味着每一次内存读或写都会创建一个需要被映射的 MemoryRegion 对象,这产生了两个影响:每秒向堆分配数百万个对象,以及为JIT编译器带来了额外的分支预测负担。他移除了可区分联合和映射函数,直接访问数组,而这 一个改变 就使他的FPS翻倍了。
后来的基准测试表明,大部分改进似乎来自于围绕分支和本地化调用点的JIT优化,因为将 MemoryRegion 改为结构体可区分联合(在栈上分配)只改善了约15%的性能,而另外85%来自于移除了可区分联合和映射函数。
还有很多次他转向使用结构体可区分联合或采用其他不那么F#风格的方法。PPU是优化变得必要的地方,他不得不在一定程度上放弃地道的F#写法。
通过定期查看性能分析器,他慢慢地提升了性能,最终达到了大约120 FPS。但随后他找到了FPS提升最大的方法。修复方法是什么?关闭调试构建,将模拟器性能提升到了闪电般的1000 FPS。他花了令人尴尬的长时间才意识到调试模式比发布模式差了那么多。即使到了最后,他也持续监控性能并进行调整。
基准测试
仅仅在控制台查看FPS数字似乎不是衡量性能的好方法。因此,在项目进行到一半时,他添加了一个 BenchmarkDotNet项目 来测量桌面性能,后来使用Node.js制作了一个简单的 网页基准测试器,以执行类似的基准测试来估计网页浏览器的性能。
基准测试都使用了以下演示ROM,用于测试真实场景:
以下是两款设备上的桌面FPS性能:一台搭载Ryzen 9 7900的Windows PC和一台搭载M4的MacBook Air。
| CPU | Flag | Roboto | Merken |
|---|---|---|---|
| Ryzen 9 7900 | 1785 | 1943 | 1422 |
| Apple M4 | 1907 | 2508 | 1700 |
以下是网页FPS性能。
| CPU | Flag | Roboto | Merken |
|---|---|---|---|
| Ryzen 9 7900 | 646 | 883 | 892 |
| Apple M4 | 779 | 976 | 972 |
Fame Boy在两个平台上的表现都相当不错。
令人惊讶的是,APU(声音)对模拟器性能的影响比PPU更大。禁用PPU使桌面性能提高了约250 FPS,而禁用APU则提高了约500 FPS。
现在是2026年,关于AI的一点说明
如今,没有代码能免受AI的影响,即使是学习项目。作者总体上力求对其AI使用保持透明,因此他想评论在一个纯粹的学习项目中,他是如何使用AI及其体验的。
在整个过程中,他主要尝试将AI作为一种辅助工具。他经常向AI请求代码审查,将其作为探讨想法的对象,并请其解释晦涩的技术文档。但他尽量减少使用AI编写的代码。他想制作一些可以向人们展示并感到自豪的东西。为人编写、由人编写的代码。如果他仅仅想要一个模拟器,他可以直接分享提示词。
在他的项目中有两个值得注意的AI使用案例。一个是在接近尾声时,他决定“挥霍”一些AI令牌,让AI命令行界面(CLI)处理他的仓库,以尝试寻找性能改进。他提供了一些想法,并要求它尝试任何它想做的。AI表现得非常好,在一些基准测试中性能提高了一倍多(相关的Pull Request链接)。但AI也引入了一些他必须修复的错误。值得注意的是,其中一个较大的性能提升(仅在模式/LY转换时更新STAT寄存器)破坏了一些依赖更频繁更新的游戏和演示(修复提交)。
另一个案例是AI在他几乎放弃时拯救了这个项目。如果你查看他仓库的git历史,会发现在某一点有一个相当大的空白期。他称之为“定时器寒冬”。
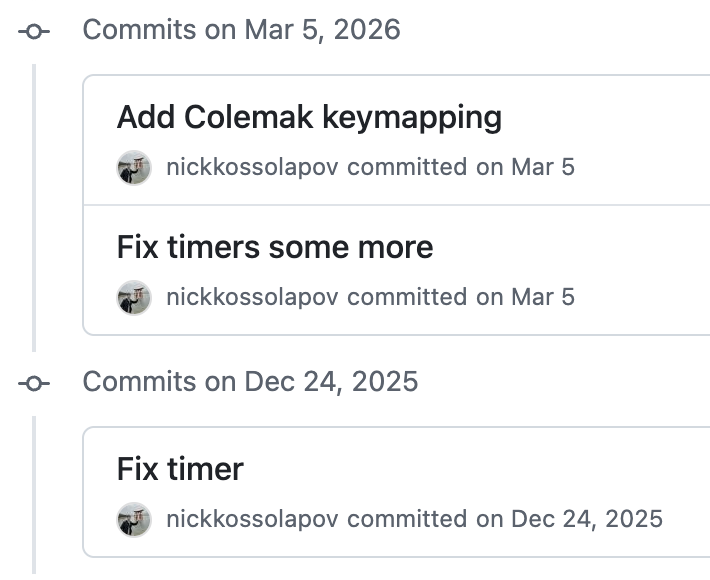
并不是他没有在模拟器上工作,而是卡在一个bug上。无论如何尝试,他都无法让《俄罗斯方块》通过版权画面。他可能花了超过20小时进行调试,扫描emu-dev Discord,创建测试,甚至把问题抛给早期的AI模型。都无济于事。但几周没碰模拟器后,他尝试了Claude Opus,它只用了几分钟就找到了问题。修复方法是什么?
let stepEmulator () =
let cyclesTaken = stepCpu cpu
// 修复前
stepTimers timer memory // 每条指令只触发一次
// 修复后
for _ in 1..cyclesTaken do // cpuCycles 可以在1到6之间变化
stepTimers timer memory这意味着定时器之前只在每条指令时滴答一次,而不是按指令所用的周期数滴答。所以它运行得比应该慢平均两到三倍,版权画面只是停留更久。天哪。显然他从未等过一两分钟来查看它实际是否会过去。
现在谈谈这篇博客本身。
在我们数字景观的广阔画卷中——一个由快速演进定义的世界——这篇博客并非只是写就,它是作为深刻的协同意向性证明而精心策划的。每一个词都是意向性细致入微的灯塔——一个用于分享脆弱感的充满活力的媒介——证明了随着我们倾身于旅程,并真实地展现自我来驾驭我们集体人类体验的复杂互动时,人与人之间的联系比以往任何时候都更重要。
清嗓子
大部分内容还是由作者自己撰写的。
我真的学到了什么吗?
他主要目标是学习计算机是如何工作的,就此而言,这是一个巨大的成功。甚至比这更重要的是,他度过了一段非常愉快的时光。下班后打开电脑时,他会想“好吧,今晚只做一个功能”。然后不知不觉就到了凌晨2点,他不断地告诉自己,修复好这个bug就去睡觉。
他曾考虑尝试Game Boy Advance,但看看规格,感觉要付出三倍的努力,而他可能只增加20%的硬件理解。他认为Game Boy在帮助他学习方面达到了很好的平衡,因此他可能暂时就此停止。
这使他成为一名更好的软件工程师了吗?可能没有。了解了他每天使用的工具多了一点后,他感觉更好了吗?当然。
感谢阅读!
如果有任何问题或评论,欢迎随时 给他发邮件。
