



背景介绍
随着纸质文件越来越不受欢迎,现在相当一部分重要数据和文件都存储在互联网上。
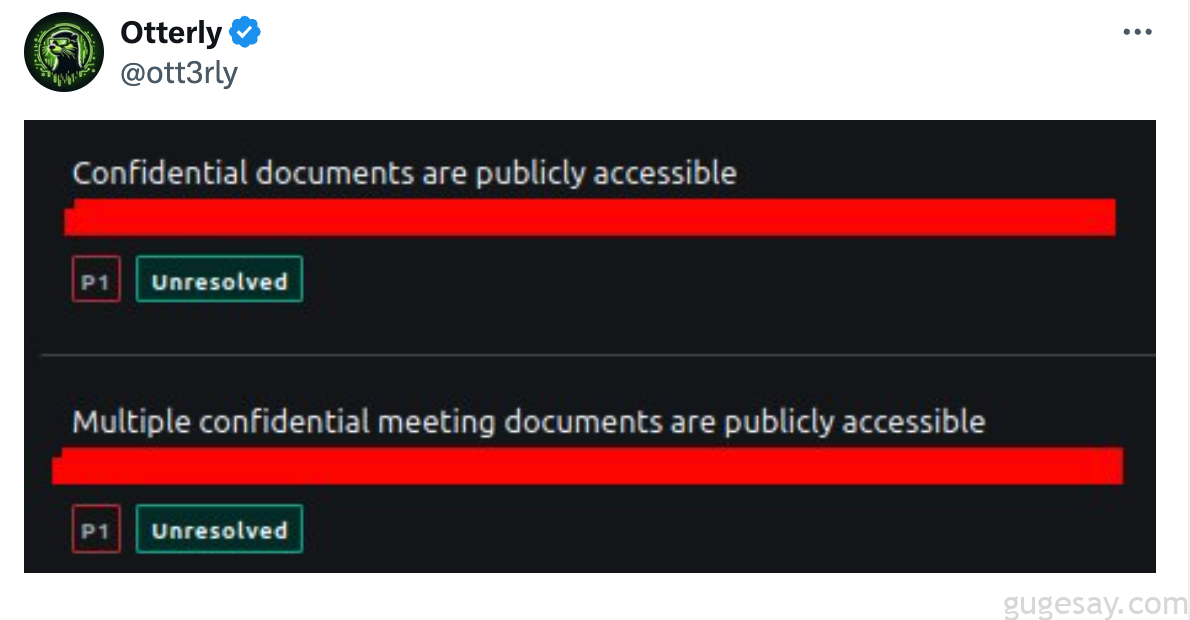
每天都有许多关于公司敏感文件泄露的消息被爆出,这些文件原本是供员工、投资者内部使用,或用于管理内部业务,如果不采取足够的预防措施,就有可能被未经授权访问。
这种事情经常会发生,尤其是在拥有数千名员工的大公司,人员数量庞大,很难确保不会发生此类事件。
而对于漏洞赏金猎人来说,这或许就是一个蕴藏‘金矿’的宝藏区,本文中将介绍国外白帽小哥如何大规模搜寻泄露敏感文件的技巧。让我们开始吧~
获取目标域
你可以一次只针对一个或几个程序来查找敏感文档的泄露,这主要取决于你的黑客风格和具体情况。
发现公共漏洞赏金计划
curl -s https://raw.githubusercontent.com/projectdiscovery/public-bugbounty-programs/main/chaos-bugbounty-list.json | jq ".[][] | select(.bounty==true) | .domains[]" -r > targets.txt上面的 bash 命令将会通过 curl 获得国外公开漏洞赏金计划列表,过滤条件会过过滤出只有赏金的项目,并从参数中仅选择域,然后将输出保存到 target.txt 文件中。
BBSCOPE 工具
如果想节省大量时间,可以单独使用该工具。但请注意,你可能需要手动检查收集到的数据。这些数据中涵盖了许多国外主流漏洞赏金平台的域目标:
H1
bbscope h1 -a -u <username> -t <token> -b > bbscope-h1.txt
BugCrowd
bbscope bc -t <token> -b > bbscope-bc.txt
Intigriti
bbscope it -t <token> -b > bbscope-it.txt
注:手动检查所有发现的数据,并将其添加到没有通配符的targets.txt和带有通配符的targets-wildcards.txt文件中。
可选项:Arkadiyt 的赏金目标数据
GitHub 上还有另一个存储库,主要用于为所有程序构建目标列表。Arkadaiyt 的漏洞赏金目标数据存储库每 30 分钟更新一次!
但是如果此存储库中的域来自 VDP 或 BBP(至少对于 domains.txt 和 wildcards.txt),遗憾的是,无法过滤该资源库中的域是否来自 VDP 还是 BBP。如果你想做个好人,而且不在乎有没有赏金报酬的话,可以按照下面的步骤操作:
curl -s "https://raw.githubusercontent.com/arkadiyt/bounty-targets-data/main/data/domains.txt" | anew targets.txt
curl -s "https://raw.githubusercontent.com/arkadiyt/bounty-targets-data/main/data/wildcards.txt" | anew target-wildcards.txt利用 VPS 批量搜索 PDF 文件
为了大规模搜索敏感 PDF 文件,可以在 Axiom 实例上安装 pdftotext CLI 程序。
关于如何管理 AXIOM 实例,可参考:https://ott3rly.com/axiom-part-3/
使用该程序,能够将 PDF 转换为文本,然后 grep 敏感词(潜在泄漏或 PII)。对于这种特殊情况,可以借助ChatGPT 来准备一个 Axiom 实例:
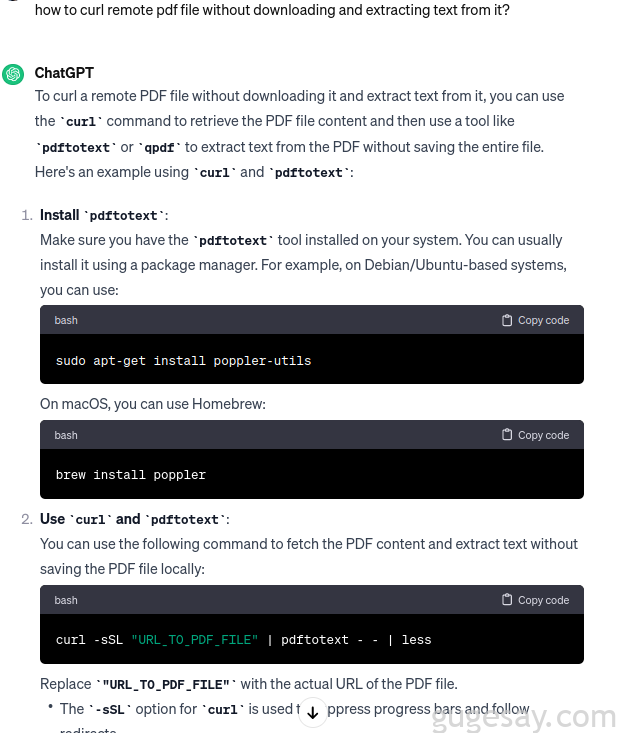
可以看到,要在每个实例上安装 pdftotext,需要使用 sudo apt-get install poppler-utils 命令将其安装在VPS上。
扫描目标以赚取利润
还可以创建了一个自定义模块,其中包含一个从包含通配符的 PDF 中收集敏感数据的单行代码:
[{
"command":"for i in `cat input | gau --subs --threads 16 | grep -Ea '\\.pdf' | httpx -silent -mc 200`; do if curl -s \"$i\" | pdftotext -q - - | grep -Eaiq 'internal use only|confidential'; then echo $i | tee output; fi; done",
"ext":"txt"
}]上面代码的作用:
- 使用 gau 收集端点,这些端点来自 wayback、urlscan 等子域
- 通过.pdf 扩展名过滤端点
- 通过httpx匹配 200 响应状态来检查是否处于活跃状态
- 对于每个活跃的端点:
- curl 该端点
- 从 PDF 转换为文本
- 搜索敏感词汇,例如internal use only(仅供内部使用)或confidential(机密)
你可以充分发挥你的创造性思维,根据自己的需求修改该脚本。
例如,使用 katana 而不是 gau,或者检查其它敏感关键词,使用其它插件/扩展等。毕竟没有一成不变的方法!
最后,使用 axiom-scan 扫描具有子域的目标:
axiom-scan targets-wildcards.txt -m gau-pdfs -anew pdf-leak-findings.txt
如果想在不包含子域的目标上使用它,则需要通过 –subs 来修改模块:
[{
"command":"for i in `cat input | gau --threads 16 | grep -Ea '\\.pdf' | httpx -silent -mc 200`; do if curl -s \"$i\" | pdftotext -q - - | grep -Eaiq 'internal use only|confidential'; then echo $i | tee output; fi; done",
"ext":"txt"
}]对没有通配符子域的目标执行命令:
axiom-scan targets.txt -m gau-pdfs -anew pdf-leak-findings.txt结语
上文介绍了国外白帽小哥如何使用一种具有创意的方法进行大规模敏感文件搜寻从而获得漏洞赏金。
你也可以尝试对其它文档类型(如 doc、docx、xlsx 等)执行同样的操作,因为这些地方同样会出现一些泄露~
这位白帽小哥的推:@Otterly
原文来自: