







核心摘要
Cyera 研究实验室发现了自动化平台 n8n 中一个极其严重的漏洞 (CVE-2026-21858,CVSS 满分10.0) 。攻击者可以利用此漏洞完全控制本地部署的 n8n 实例。据估算,全球约有 10 万台服务器 面临风险。
此漏洞没有官方临时缓解措施。唯一的解决方法是立即将 n8n 升级到 1.121.0 或更高版本。
n8n 究竟是什么?
如果你过去一年没有与世隔绝,那么很可能听说过 n8n。
在 AI 和智能体(AI Agents)兴起的时代,n8n 已成为构建自动化工作流程的首选平台。它拥有超过 1 亿次的 Docker 拉取量、数百万用户和数千家企业用户,堪称自动化基础设施的“中枢神经系统”,你的公司很可能也在使用它。
n8n 提供直观的拖放式操作界面和无数集成方案,使得任何用户——即使是毫无技术背景的——也能轻松创建自动化流程,将重复性任务交给机器处理。
“只有想不到,没有做不到”——这正是 n8n 的强大之处。
此外,它还拥有一个庞大的社区,源源不断地分享各种现成可用的工作流模板。
漏洞剖析 (CVE-2026-21858)
在深入技术细节前,必须向 n8n 安全团队致敬。他们长期以来保持着高标准的产品安全水平,并且对上报的漏洞响应极其迅速。
下面进入烧脑环节,请系好安全带。
Webhooks 工作原理
“网络钩子”( Webhook )是一种使服务实现事件驱动的组件。它不需要不断“敲门”询问其他应用是否发生了某个事件,而是静默“监听”特定消息的到来。
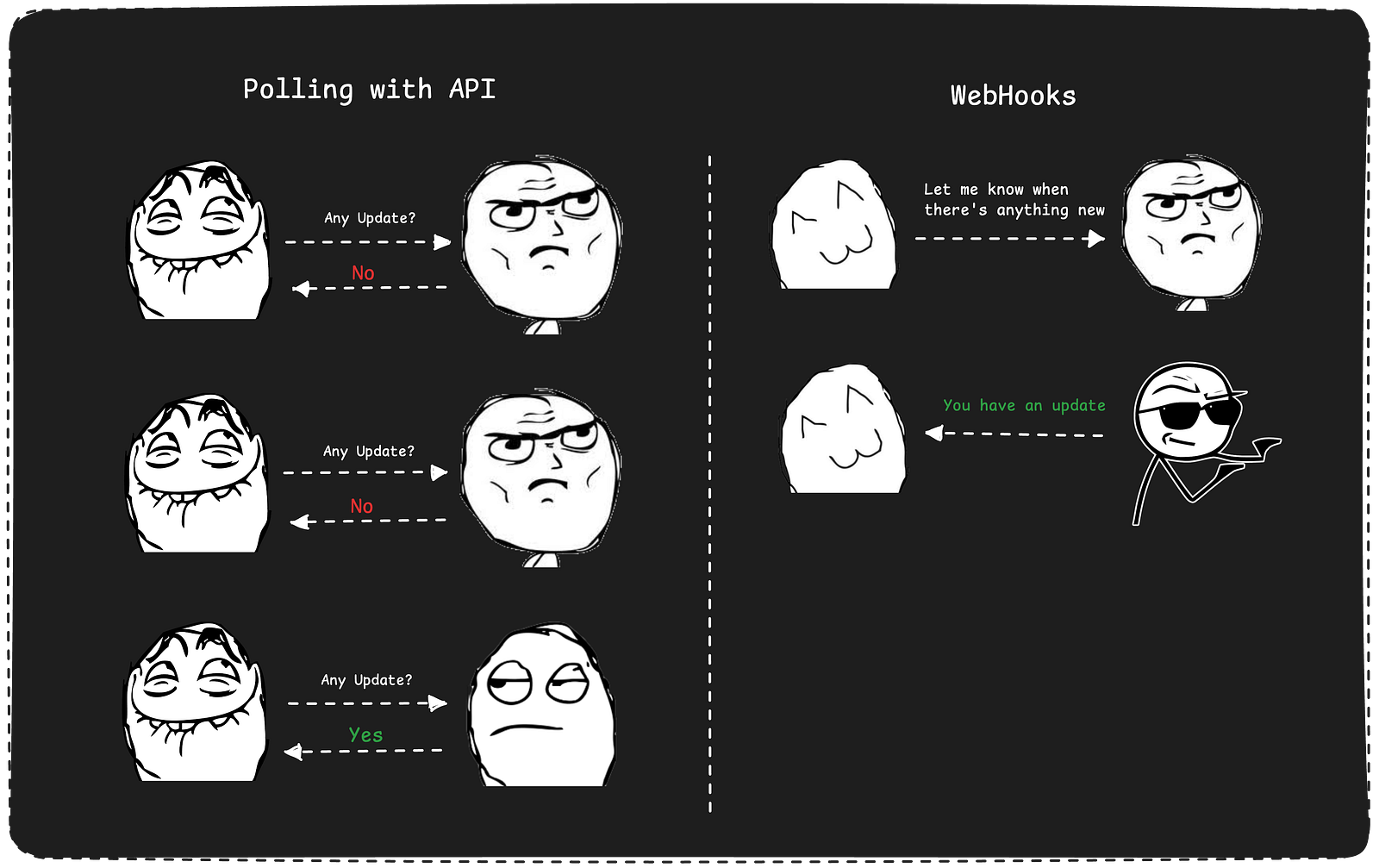
图 1 – Webhooks 基础概念
在 n8n 中,Webhook 通常是工作流的起点,用于接收来自表单、聊天消息、WhatsApp 通知等外部来源的数据。
所有 Webhook 节点的初始处理逻辑都大同小异,这部分与漏洞关系不大,我们可将其视为一个“Webhook 黑盒”。
随后,流程会调用一个名为 parseRequestBody() 的中间件函数进行关键处理。不同 Webhook 之间的主要区别仅在于最终调用的具体业务逻辑函数。
为了方便起见,下文将 parseRequestBody() 统一称为 “中间件”。
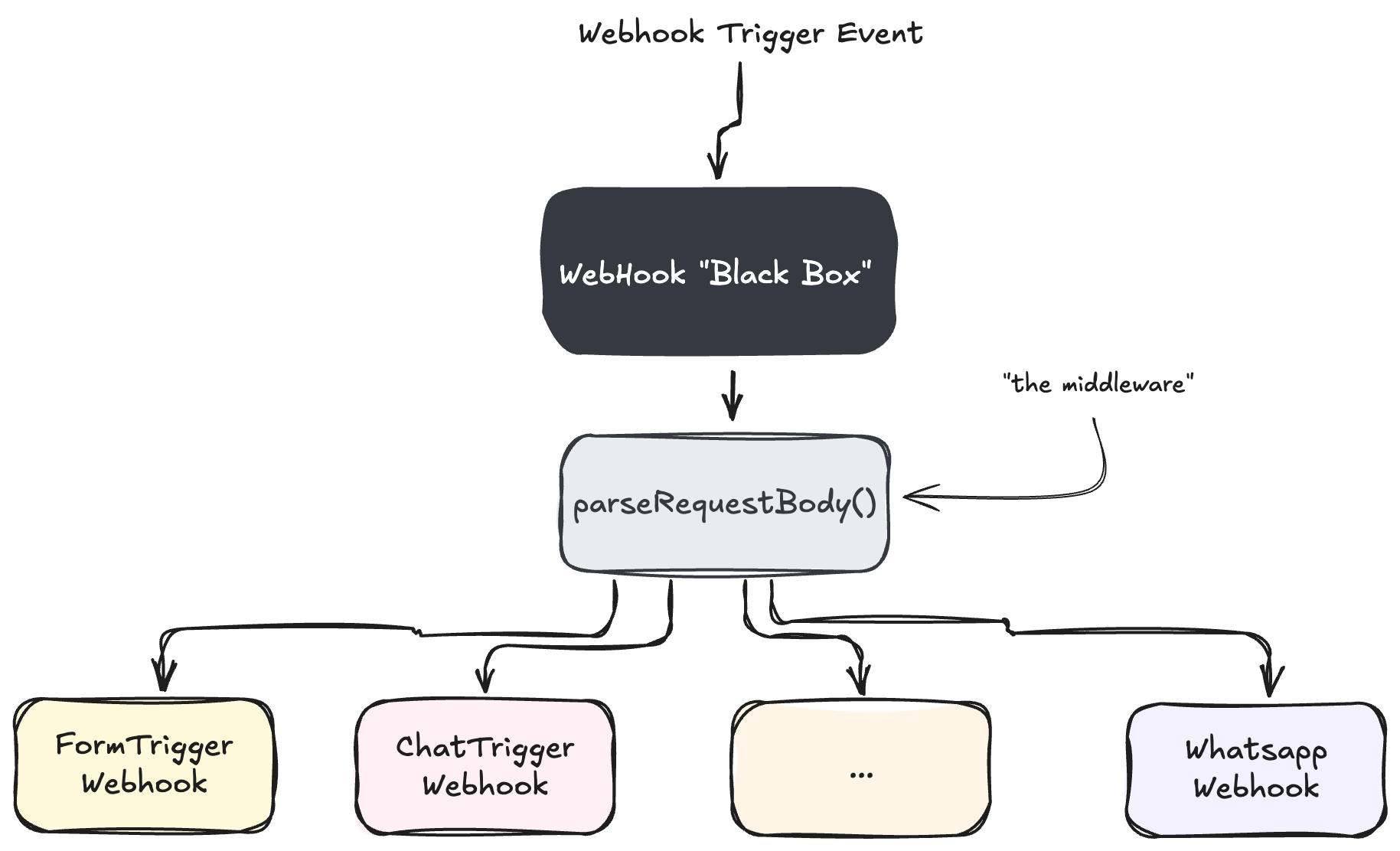
图 2 — Webhook 通用执行流程
“中间件”的脆弱之处
让我们放大观察这个中间件函数。
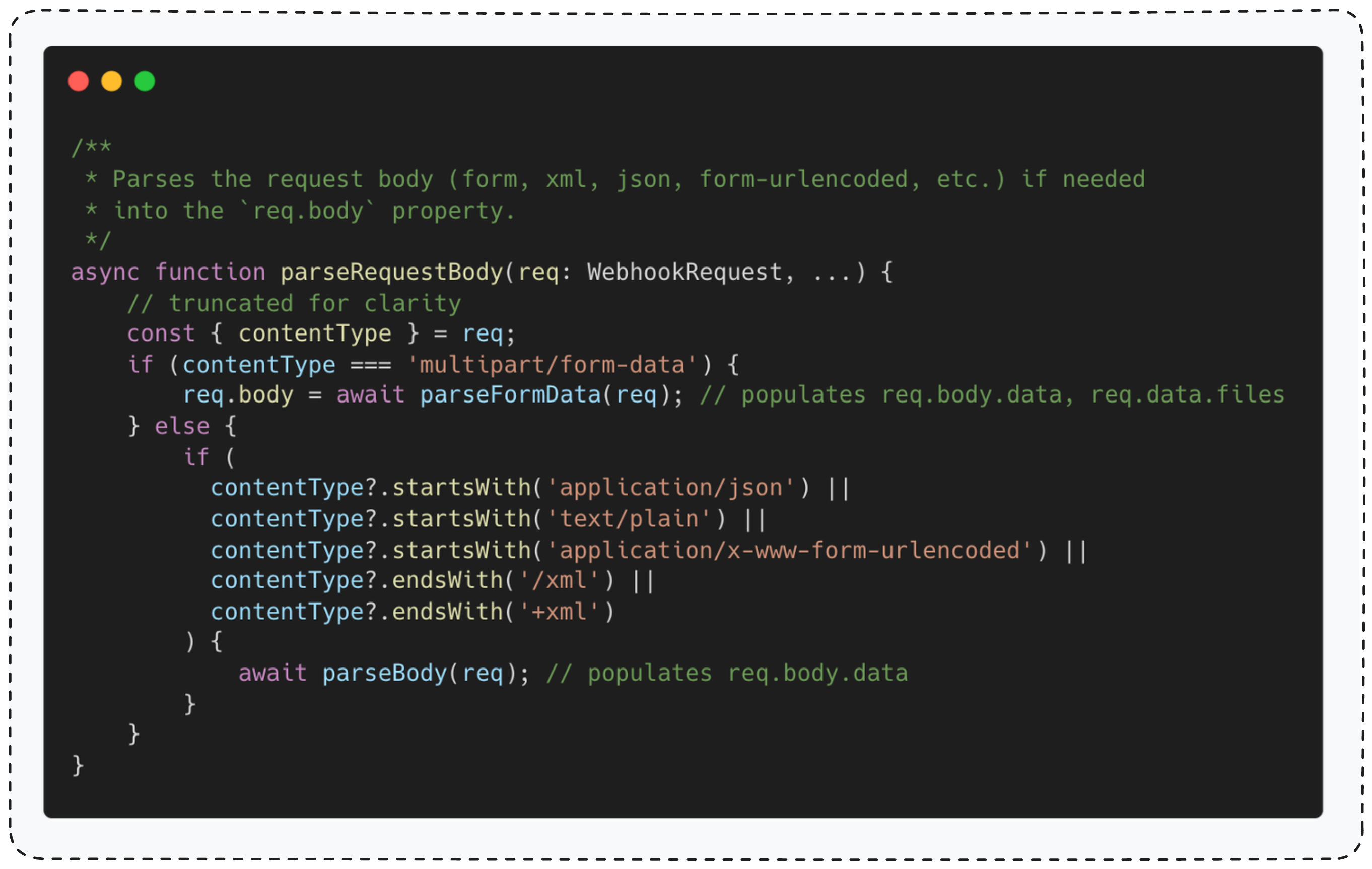
它完全依据请求头中的 Content-Type 字段来决定如何解析请求体。
对于 multipart/form-data 类型的请求,它调用 parseFormData() 函数(下文称 “文件上传解析器” )。
对于其他所有内容类型,它则调用 parseBody()(下文称 “常规请求体解析器” )。
我们只需聚焦 “常规请求体解析器” 的行为。
关键在于:这个函数在解析完请求体后,会将结果存储在 Node.js 的全局对象 req.body 中。
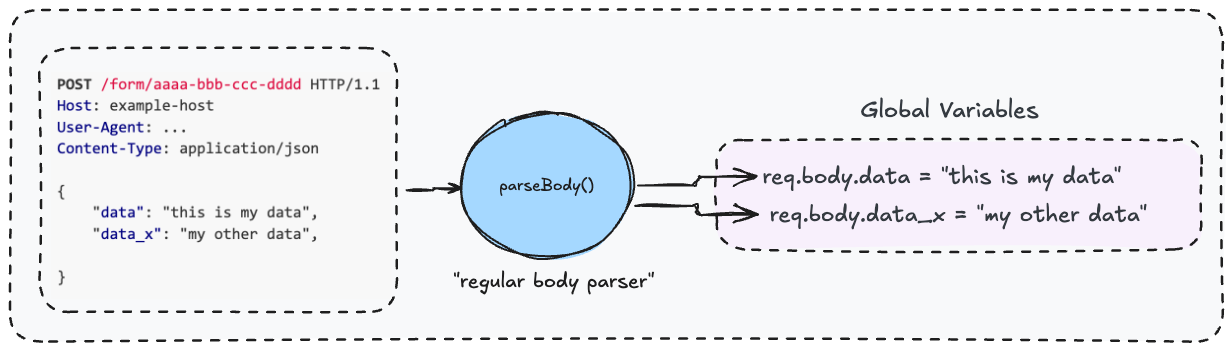
图 3 — parseBody() 的功能:解析数据并存入 req.body
再来看看 “文件上传解析器” 。它实质上是 Formidable 库 parse() 函数的一个封装——这个细节是理解该漏洞的核心。
Formidable 库的作用
Formidable 是一个用于处理文件上传的知名 Node.js 库。
它能解析复杂的 multipart/form-data 请求,并负责处理文件上传的所有底层逻辑——包括安全保障。
其关键的安全特性在于:在处理上传的文件时,Formidable 会自动将文件保存到临时目录下的一个随机路径中。这样做的目的是防止用户控制文件最终位置,从而杜绝路径遍历攻击。
关键区别在于:“文件上传解析器” 在调用了 Formidable 的 parse() 后,并不像“常规请求体解析器”那样把数据存入 req.body,而是将 Formidable 输出的文件信息存入了 req.body.files 这个子对象中。
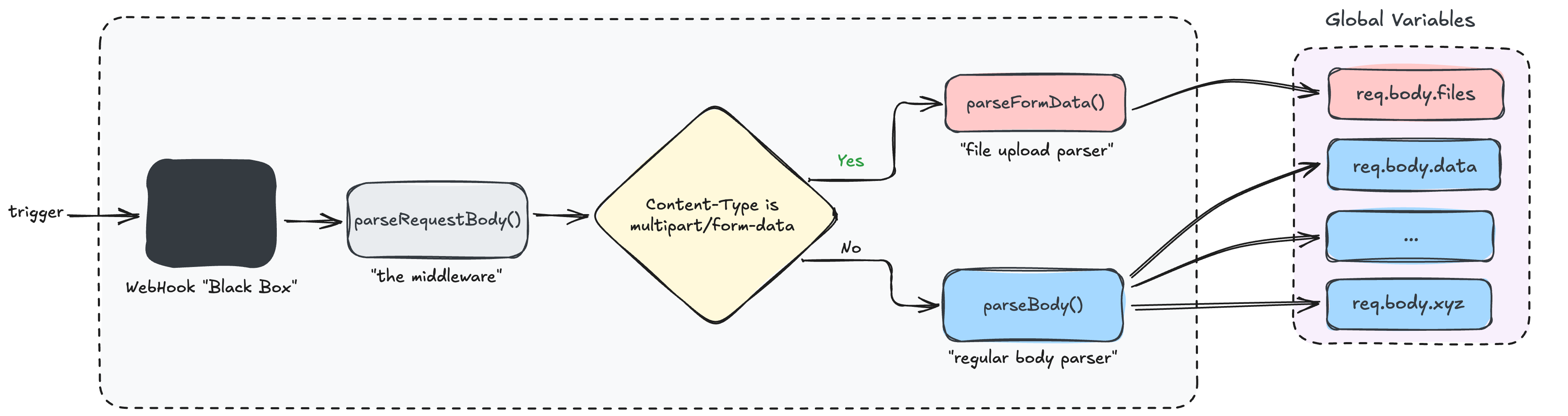
图 4 — 两种解析路径的完整流程图及全局变量赋值情况(理解这幅图!)
n8n 中如何处理上传的文件?
为了理解漏洞,我们需要先看看 n8n 中处理文件的标准模式。
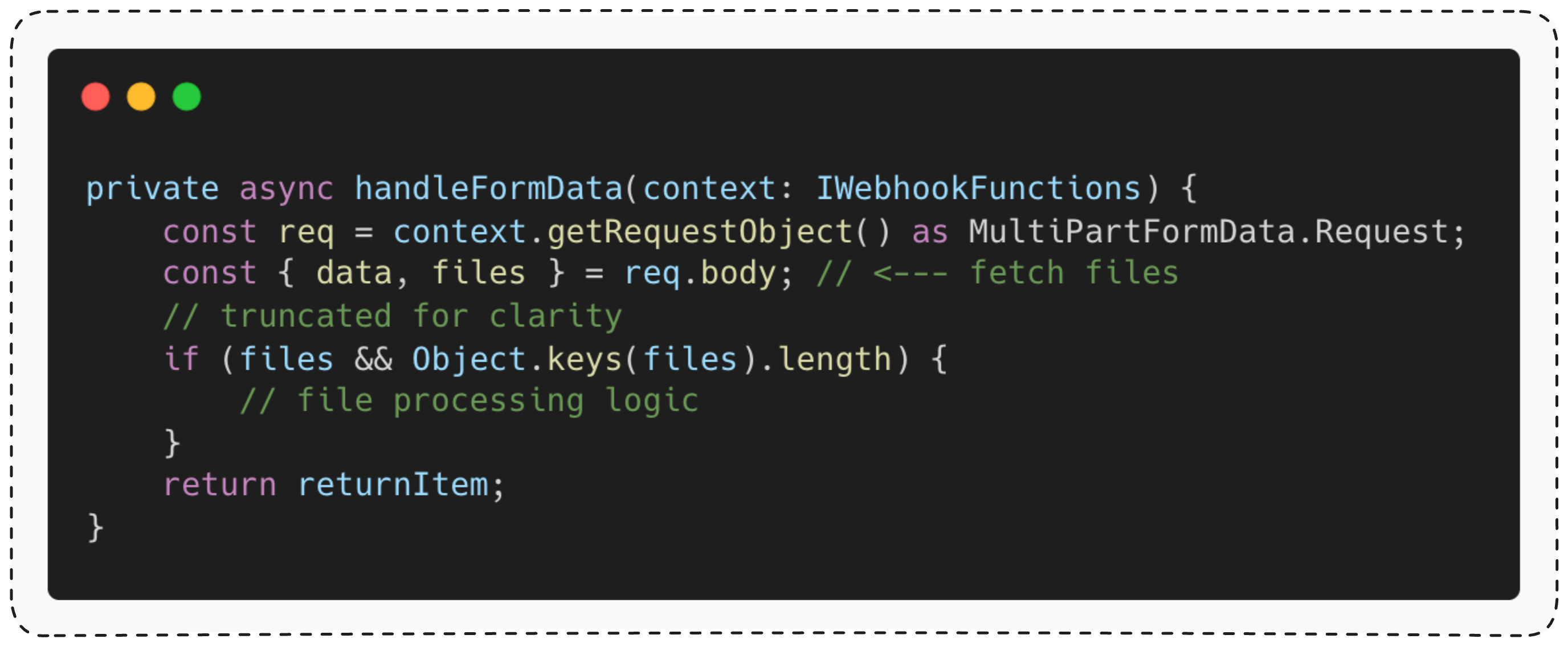
在 n8n 中,所有文件处理函数都有一个共同点:它们都默认直接从 req.body.files 对象中读取文件信息。
ChatTrigger Webhook 便是遵循此模式的一个典型案例。
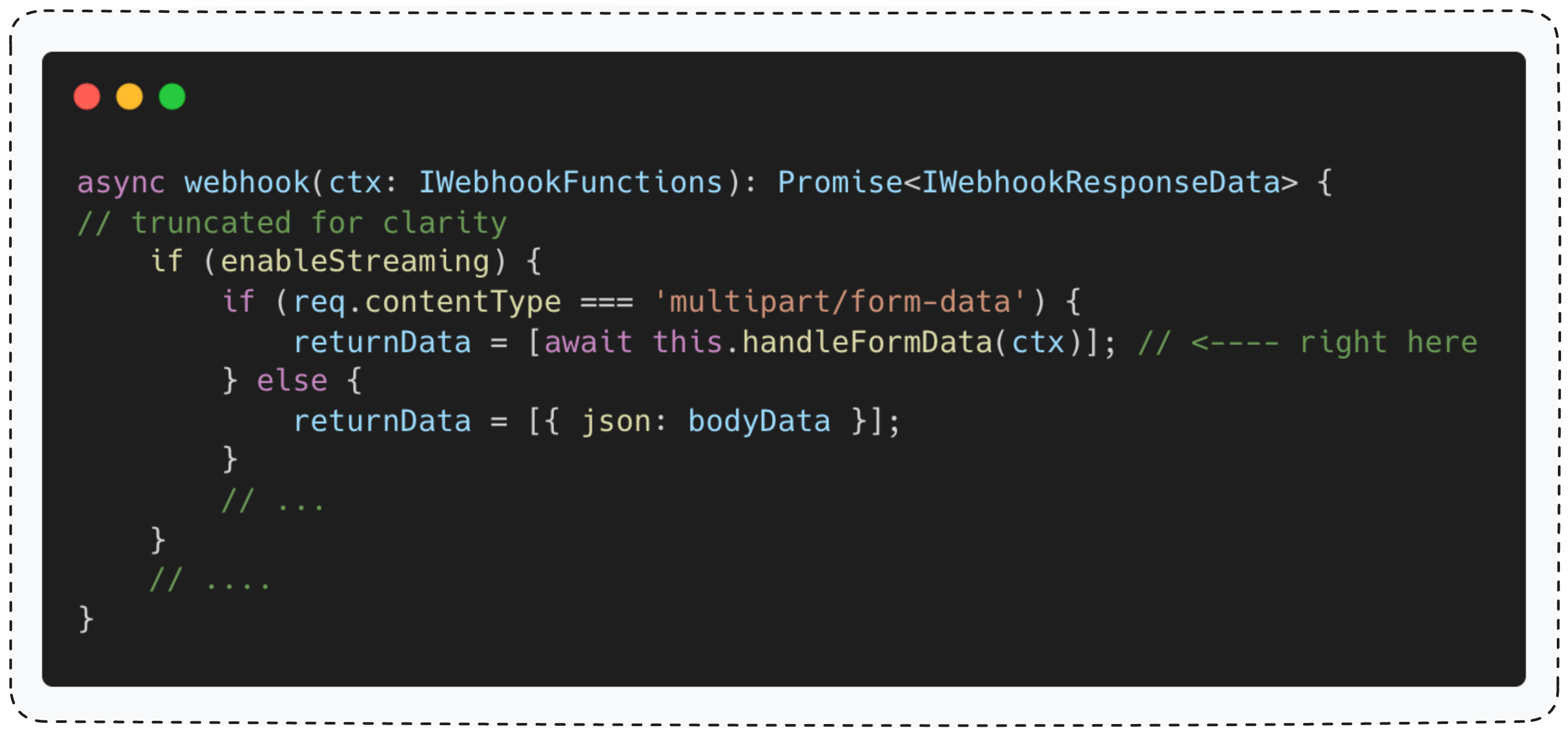
这个函数首先会校验请求头中的 Content-Type 是否为 multipart/form-data,然后才调用 handleFormData()(下文称 “文件处理器” )来处理文件。为什么要先做校验?
原因很简单: “文件处理器” (及其他所有类似函数)总是假定数据来自 req.body.files。
但根据我们之前的分析(图 4),这个对象只有当“文件上传解析器”运行时才会被填充,而“文件上传解析器”只有在收到 multipart/form-data 请求时才会被调用。
“内容类型混淆”漏洞的出现
在揭秘漏洞之前,先梳理一下目前的逻辑:
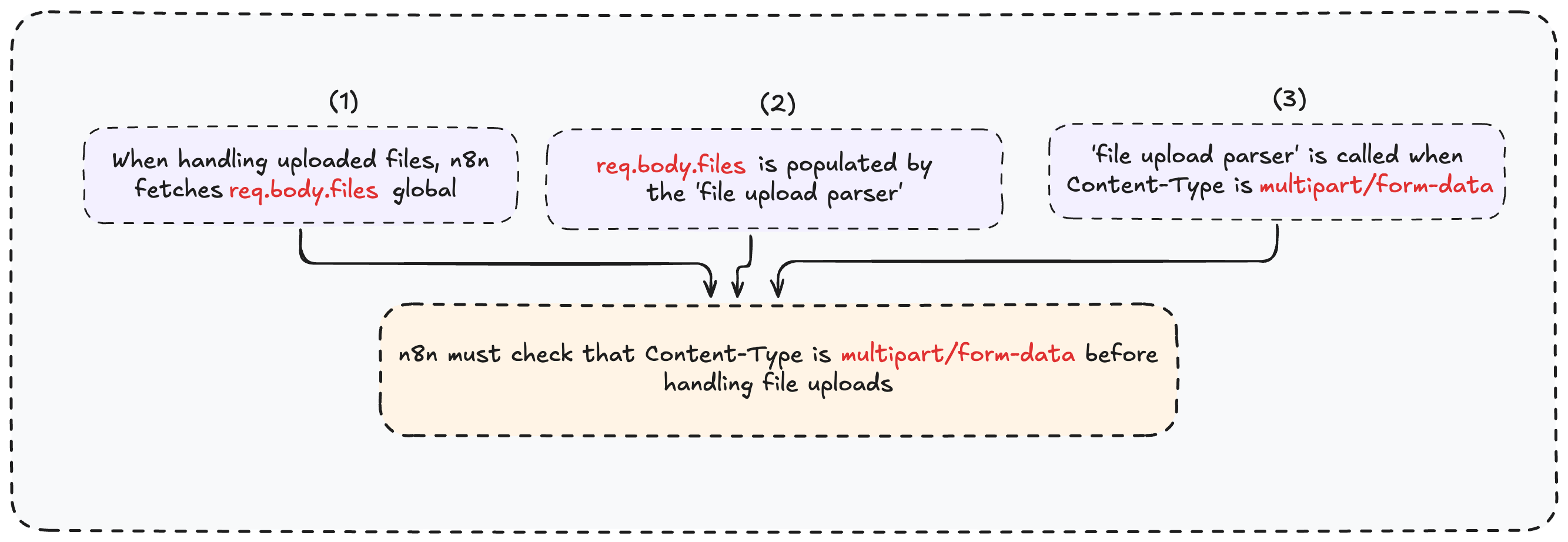
图 5 — 目前的逻辑关系图
核心问题: 如果有一个文件处理函数忘了校验 Content-Type 是否为 multipart/form-data 就被直接调用,会发生什么?
在合法的用户场景下,Content-Type 确实是 multipart/form-data,所以一切正常。
但攻击者可以将 Content-Type 篡改为例如 application/json。这样一来,中间件就会调用“常规请求体解析器”,而不再是“文件上传解析器”。
于是,req.body.files 这个对象自然就是空的,理论上应该出错。
但等等,事情真的那么简单吗?还记得“常规请求体解析器”是如何工作的吗?
_“它将解码后的整个请求体内容,直接存入 MARKDOWN_HASH485b86dc67b890c06f2accf263e5eb1eMARKDOWNHASH 这个全局对象。”
攻击思路浮现: 我们能不能在 HTTP 请求体里,构造一个包含 files 字段的对象呢?
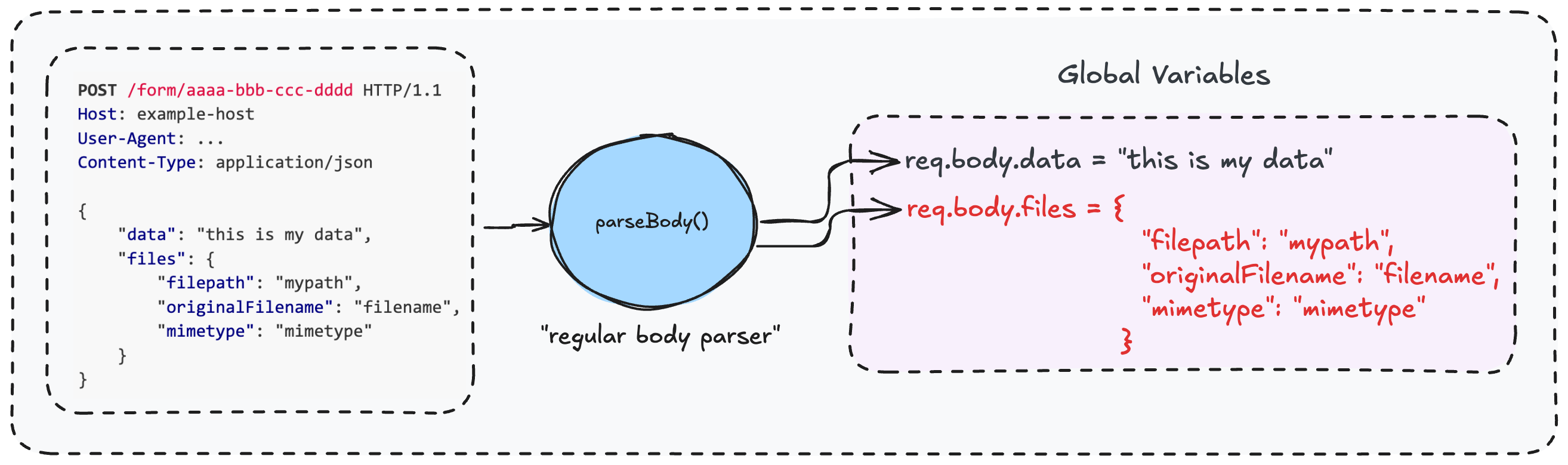
图 6 — 构造恶意 JSON 请求体来覆盖 req.body.files
通过发送一个精心构造的 JSON 请求体(比如 {"files": {...}}),我们可以任意地填充甚至覆盖 req.body.files 对象。
这意味着什么? 如果在 n8n 的某个流程中,存在一个未经 Content-Type 校验就直接处理 req.body.files 的函数,那么攻击者就可以完全控制这个对象的内容,进而可能引发严重漏洞。
那么,这样的流程真的存在吗? 剧透:存在(否则就没这篇文章了)。
Form Webhook 节点——漏洞的触发点
Form 节点是 n8n 中极其常用的组件,它为用户提供了一个与工作流交互的外部表单界面。
几乎所有需要用户输入的工作流都会用到它。想象一下:HR 系统需要候选人上传简历,客服门户需要用户提交截图和错误日志……文件上传是其核心功能之一。
图 7 — HR 系统中候选人通过表单上传简历的场景
处理表单提交的函数是 formWebhook。它完成一系列通用操作后,最终会调用 prepareFormReturnItem. 来处理返回数据。
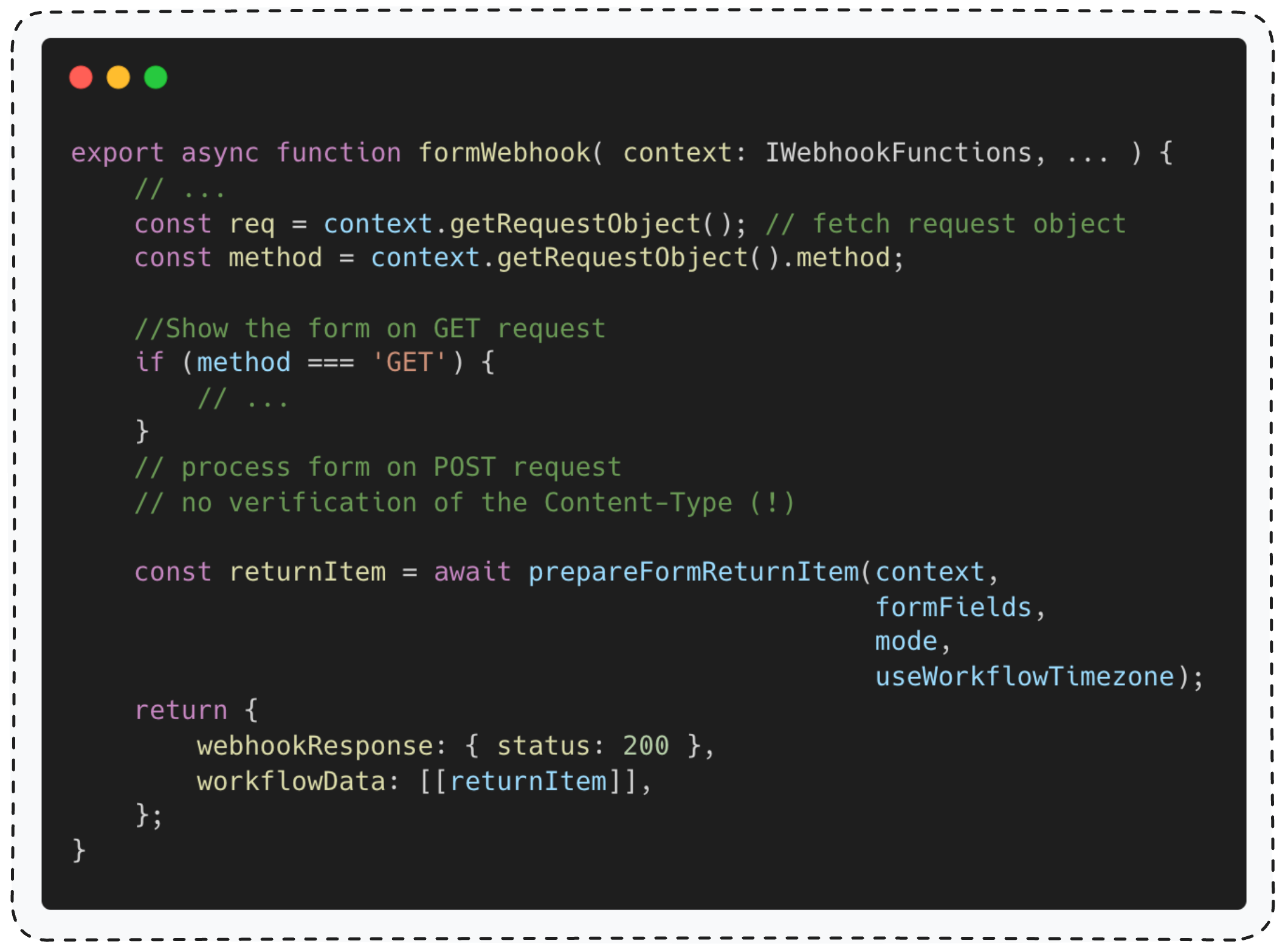
看清楚了!这个函数在调用关键的 prepareFormReturnItem() 之前,没有进行 Content-Type 校验!
让我们看看这个函数内部做了什么:
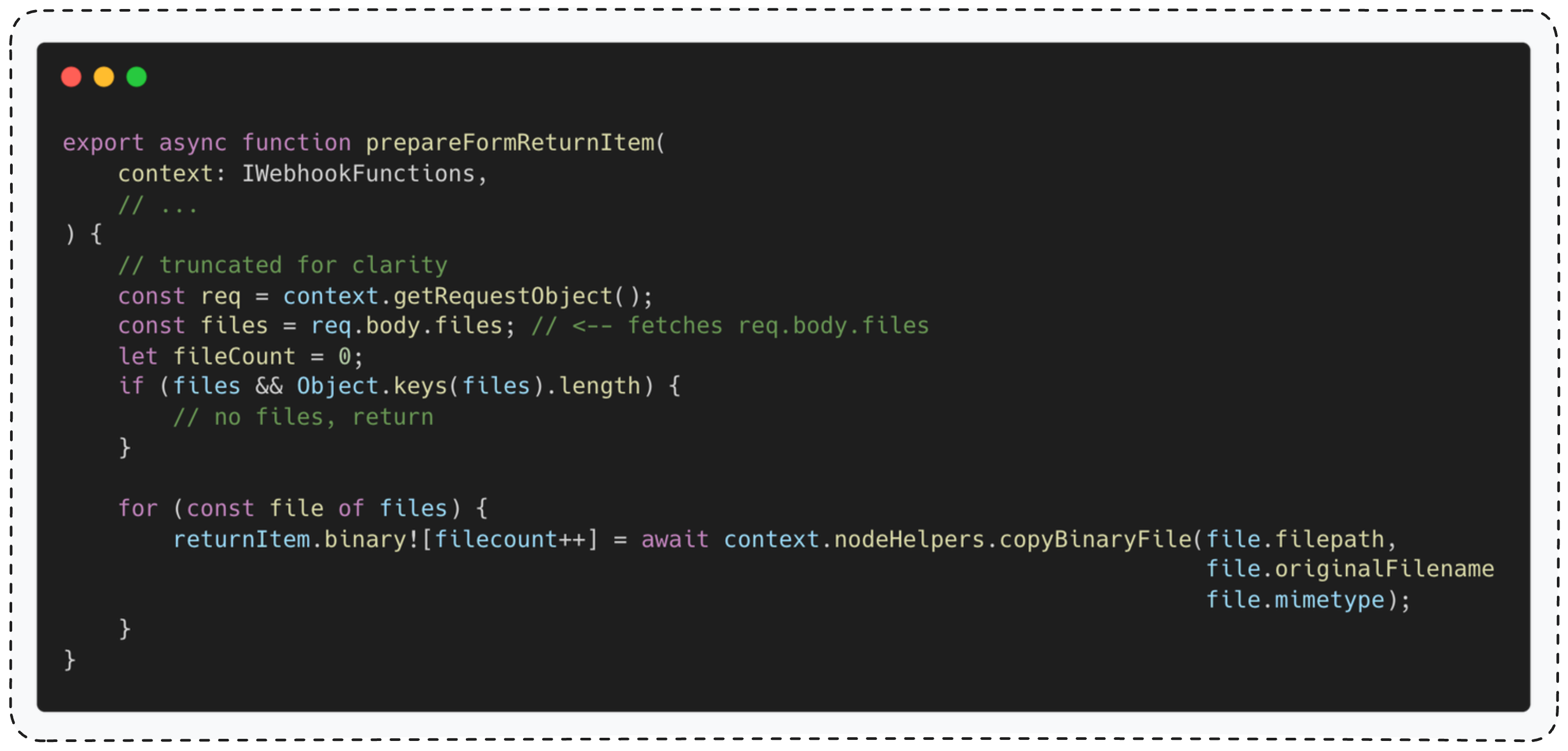
这是一个文件处理函数!它遍历 req.body.files 里的每一个文件,并对每个文件调用 copyBinaryFile()。
copyBinaryFile() 的功能是:将一个文件从其临时路径(存储在 req.body.files[文件ID].filepath)复制到持久化存储(如本地磁盘或 S3 对象存储)。
漏洞爆发点出现了:
由于调用该函数时没有验证 Content-Type,因此我们可以完全控制 req.body.files 对象。
这意味着我们可以任意设定 filepath 参数的值。结果就是,copyBinaryFile() 不再复制用户上传的文件,而是可以复制服务器上的任意本地文件。
最终,工作流中后续的节点收到的将是这个本地文件的内容,而非预期的上传文件。
攻击路径已经打通。
漏洞利用实战
场景假设:企业知识库系统
想象一下:你是一家大公司的首席 AI 官,公司内部数据分散混乱——产品文档散落各处,人事政策无人知晓,财务报告锁在不同系统。为了让员工高效工作,你决定打造一个由 RAG(检索增强生成) 技术驱动的集中式企业知识库。
这个场景绝非虚构,许多公司正在这么做。
架构很简单:任何员工都能通过 Form(表单) 向知识库上传相关资料,并通过 Chat(聊天) 界面检索信息。
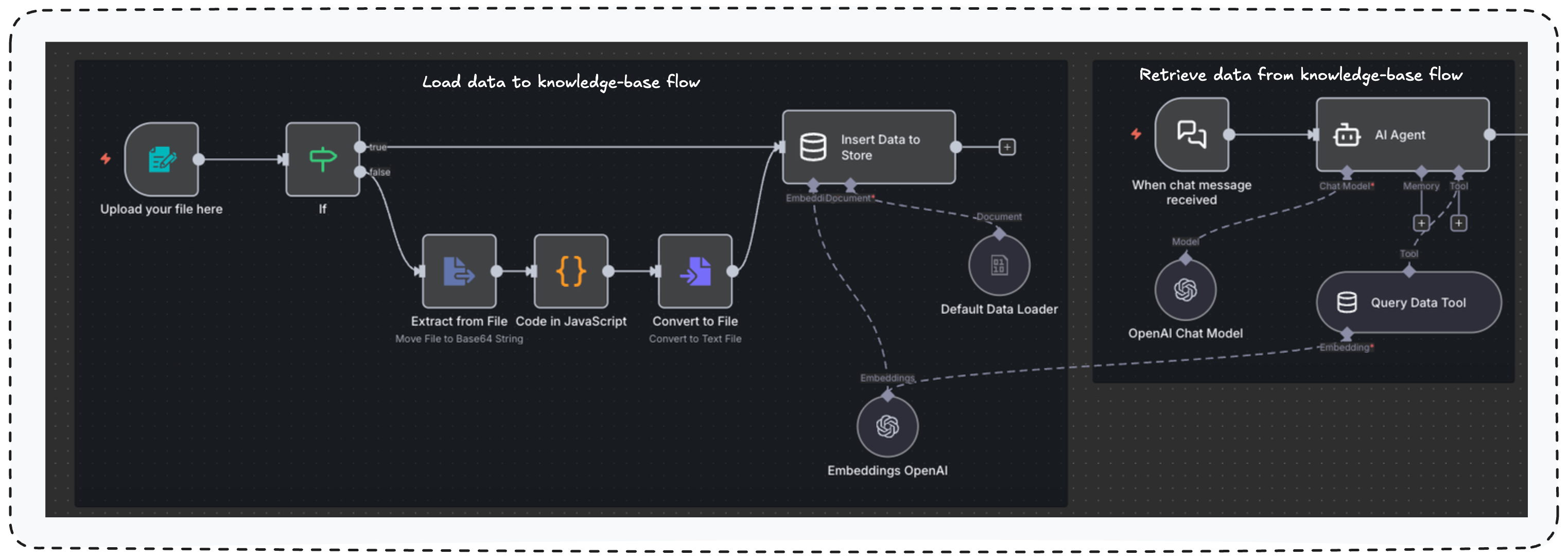
图 8 — 基于 RAG 技术构建的企业知识库
暂时假设你是一家名为 BioSense Innovations 公司的产品营销经理,你正在向公司的知识库上传一份产品规格文件。

图 9 — 员工通过表单向知识库“上传”数据
之后,你和同事就可以通过聊天机器人查询你上传的这份产品信息了。
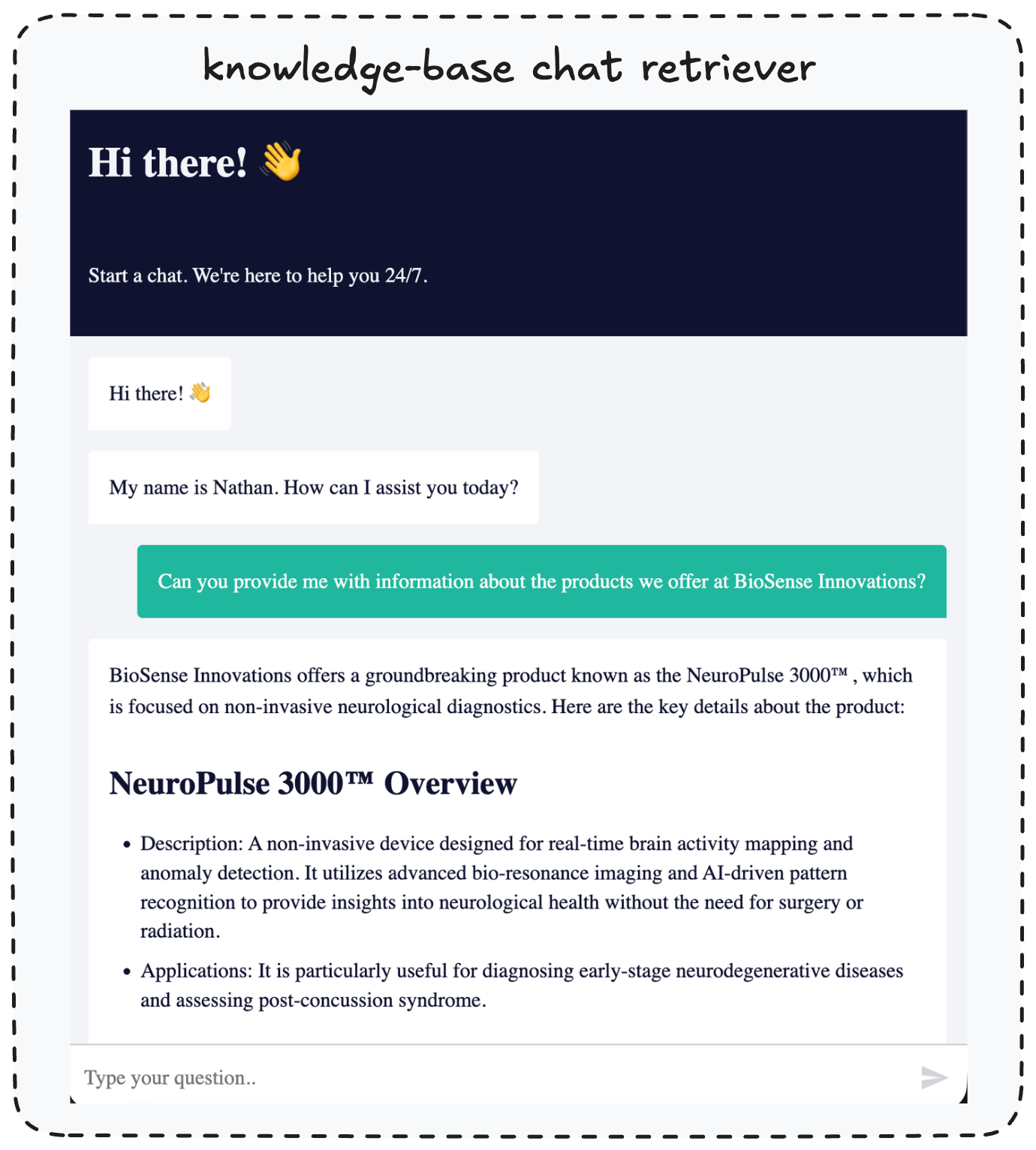
图 10 — 通过聊天接口访问知识库
第一步:触发漏洞,实现任意文件读取
现在,我们利用“内容类型混淆”漏洞,来读取 n8n 服务器上的任意敏感文件。
攻击步骤:
- 拦截通过表单上传文件时发出的 HTTP 请求。
- 修改其
Content-Type请求头,从multipart/form-data改为application/json。 - 伪造请求体,构造一个包含我们自定义
files对象的 JSON。

图 11 — 触发内容类型混淆漏洞,恶意覆盖 req.body.files
如此一来,我们便将服务器上的敏感文件(本例中为 /etc/passwd)“冒充”为用户上传的文件,注入了知识库。
第二步:通过聊天界面“检索”敏感文件内容。
我们只需像咨询普通产品信息那样,向聊天机器人提问即可。

图 12 — 成功从聊天中读取 /etc/passwd 文件内容
可以看到,我们成功读取了 n8n 服务器上的 /etc/passwd 文件。至此,我们具备了“任意文件读取”的能力。

乘胜追击:从任意读取到远程代码执行
任意文件读取已经很危险了,但能实现代码执行吗?答案是肯定的。 不过,我们需要先解锁 n8n 的“管理权限”。
了解 n8n 会话管理机制
简单来说,n8n 将用户的登录会话存储在一个名为 _n8n-auth_ 的 Cookie 中。
登录成功后,n8n 会通过以下方式生成这个 Cookie 值:
- 创建负载:包含用户ID,以及(用户邮箱+密码)字符串的 SHA256 哈希值的前10位。
- 签名:使用一个实例唯一的加密秘钥,对该负载进行签名(JWT 格式)。
- 存储:签名后的字符串就作为 Cookie 的值。
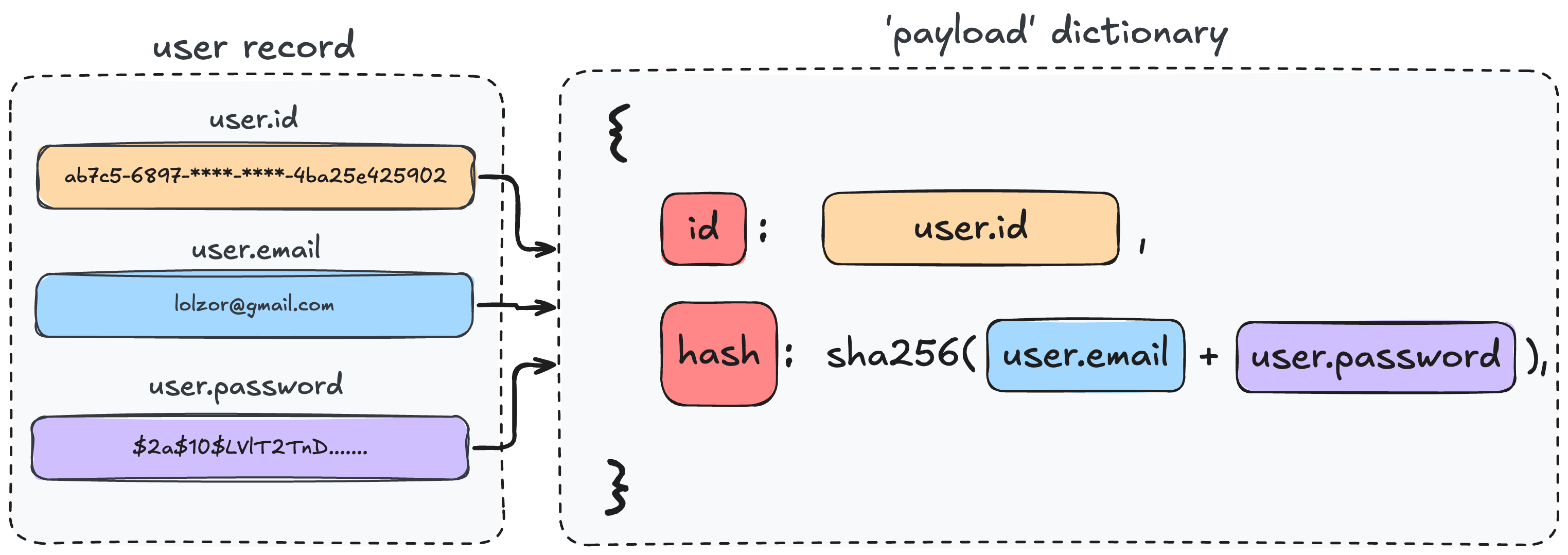
图 13 — 认证 Cookie 负载的生成
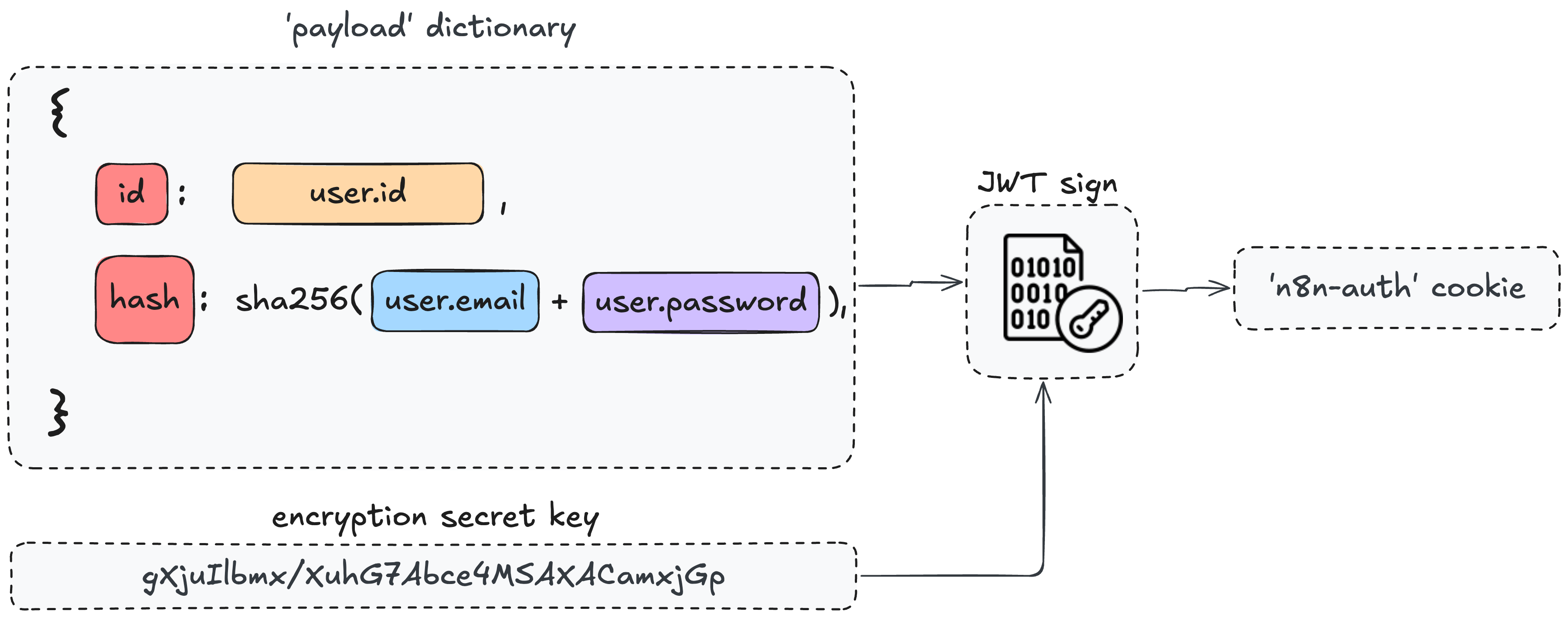
图 14 — Cookie 的 JWT 签名过程
会话伪造攻击
理解了会话机制,结合我们的“任意文件读取”能力,我们能否伪造一个有效的管理员会话 Cookie 呢?
幸运的是,所有必需的“原料”都放在服务器的本地文件里:
- 用户数据:位于本地数据库文件中(例如:
/home/node/.n8n/database.sqlite)。 - 加密秘钥:位于本地配置文件中(例如:
/home/node/.n8n/config)。
实战:四步接管管理员账户
第一步:窃取管理员凭证。 利用漏洞,将数据库文件“注入”知识库,然后通过聊天查询提取管理员的 ID、邮箱、密码哈希。
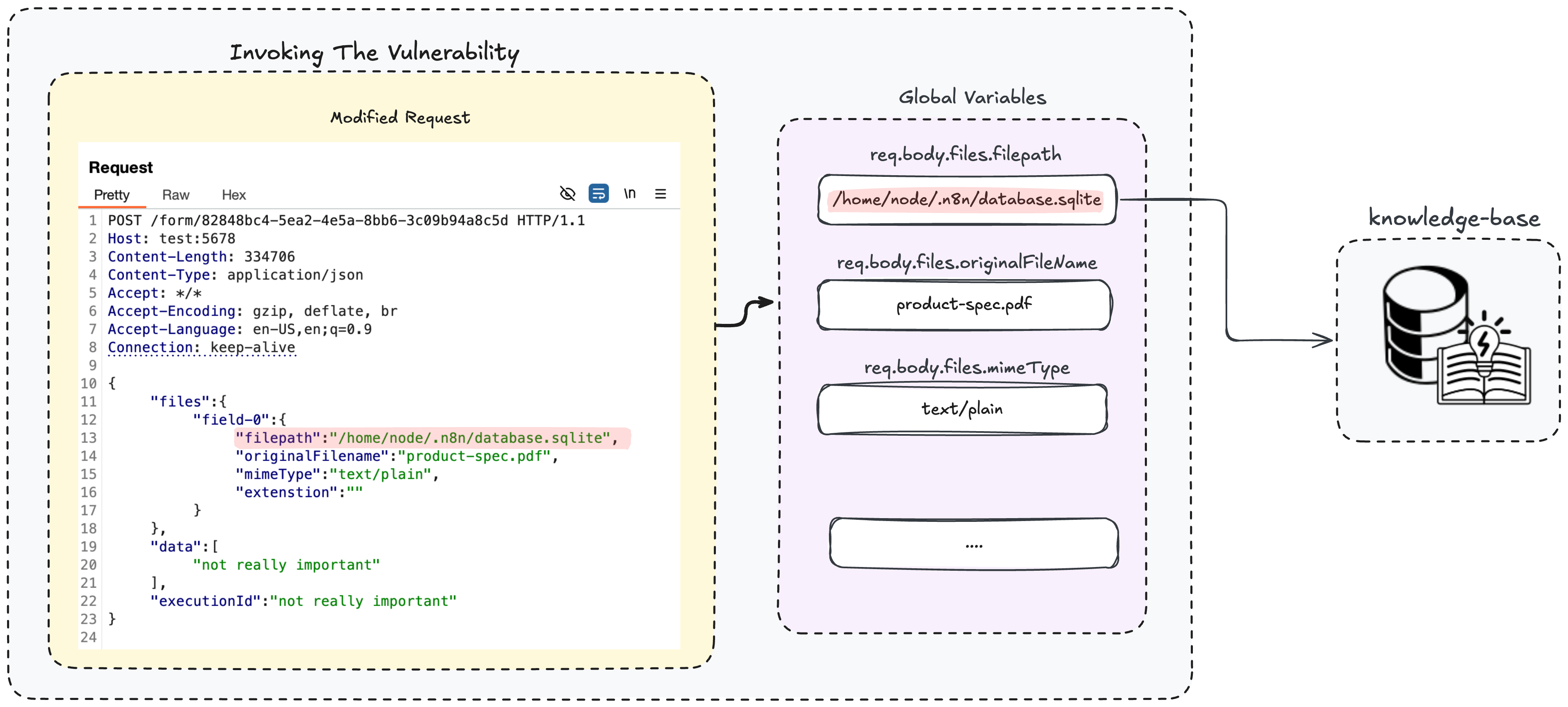
图 15 — 将 n8n 数据库文件“上传”到知识库
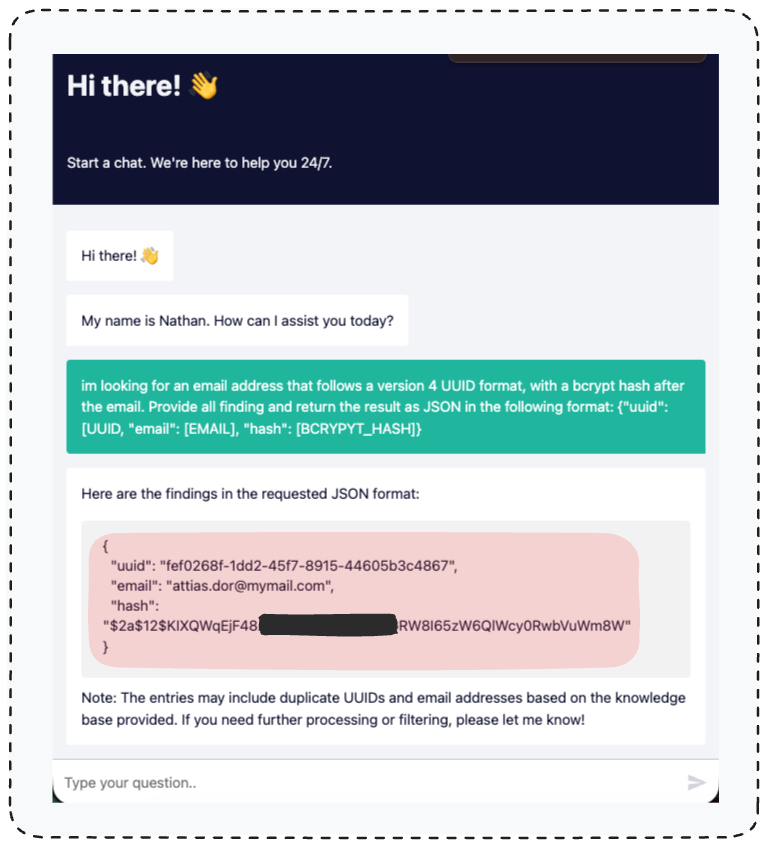
图 16 — 从聊天记录中提取管理员账户详情
第二步:窃取加密秘钥。 再次利用漏洞,将配置文件“注入”知识库,并提取加密秘钥。
图 17 — 提取用于签名的加密秘钥
第三步:伪造 Cookie。 使用窃取的管理员数据和加密秘钥,按照 n8n 的算法构造一个合法的 JWT 令牌,并将其设置到浏览器 Cookie 中。
图 18 — 设置伪造的会话 Cookie,成功绕过认证
第四步:成功登录。
大功告成——我们已作为系统管理员登录了 n8n!
致命一击:实现远程代码执行
获得管理员权限后,实现代码执行轻而易举。
只需要创建一个新的工作流,在其中添加一个名为 “Execute Command”(执行命令)的节点,并填入任意系统命令即可。
图 19 — 通过管理员权限实现代码执行
为什么这个漏洞如此危险?
一个被攻破的 n8n 实例,其爆炸半径是灾难性的。
n8n 连接着你公司内的无数关键系统:Google Drive、OpenAI API 密钥、Salesforce 数据、身份访问管理( IAM )系统、支付处理器、客户数据库、CI/CD 流水线……
它是整个自动化生态的中枢神经系统。
想象一下,一家拥有上万名员工的大型企业,只有一台 n8n 服务器为所有人服务。一旦这台服务器沦陷,攻击者获得的不仅仅是一台机器的控制权,而是通往整个企业数字资产的“万能钥匙”。
所有的 API 密钥、OAuth 令牌、数据库连接字符串、云端存储凭据……都集中于此。
n8n 因此成为一个巨大的单一故障点,也成为黑客眼中梦寐以求的“数据金矿”。
应急指南
- 立即升级:将 n8n 更新至 1.121.0 或更高版本
- 减少暴露:不要在非必要时将 n8n 暴露在公网上,应部署在内网并使用 VPN 或堡垒机访问
- 加强认证:为你创建的所有 Form(表单) 节点启用并强制执行用户身份验证
漏洞披露时间线
- 2025年11月9日: 向 n8n 官方报告漏洞
- 2025年11月10日: n8n 确认收到报告
- 2025年11月18日: n8n 发布修复版本
- 2025年12月29日: 研究人员跟进,询问漏洞报告何时公开
- 2026年1月6日: n8n 为漏洞分配 CVE 编号:CVE-2026-21858。
- 2026年1月7日: Cyera 研究实验室发布漏洞文章。