










凌晨三点,某家科技公司的服务器安静地运转着。代码库里躺着几十万行代码,没人知道其中藏着一个刚刚被公开的漏洞。
与此同时,一行代码都没敲,一个黑客都没出手——但AI模型已经发现了它。
这不是科幻,而是N-Day-Bench正在测试的现实。
漏洞江湖里的"公开秘密"
先说个背景。
安全圈子里有个术语叫N-Day漏洞,听起来玄乎,说白了很好理解:
一个漏洞被人挖出来了,PoC(概念验证代码)在网上流传,安全社区都知道它存在,但厂商还没来得及修——这段时间,就是N-Day窗口期。

问题是:找出来了吗?谁来当这个"发现者"?
以前靠安全研究员,靠白帽子,靠代码审计。现在,可能要加上一类新角色——AI模型。
而N-Day-Bench,就是专门测这个事的。
一场"反常识"的考试
传统的AI编程benchmark考什么?写代码、做算法题、答编程题。
但你发现了没有:能写代码≠能找漏洞。
一个模型HumanEval拿满分,也不代表它能识别出一个缓冲区溢出。写代码考的是"创造",找漏洞考的是"发现"——这是两种完全不同的思维方式。
N-Day-Bench的核心设计很直接:
- 给你一段代码
- 给你一个CVE编号
- 看你能不能自己找到漏洞在哪
关键来了——这个漏洞必须是模型"知识截止日期"之后才出现的。考的是真本事,不是背答案。
就像考试前没发过任何复习资料,全凭你现场分析一段陌生的代码,找出藏在里面的问题。
这难度,可比做几道理工科数学题刺激多了。
榜单出炉,有人欢喜有人愁
好,上结果。
最新一期N-Day-Bench榜单(简要版):
| 排名 | 模型 | 得分 |
|---|---|---|
| 🥇 | OpenAI GPT-5.4 | 83.93 |
| 🥈 | 智谱 GLM-5.1 | 80.13 |
| 🥉 | Anthropic Claude Opus 4.6 | ~80 |
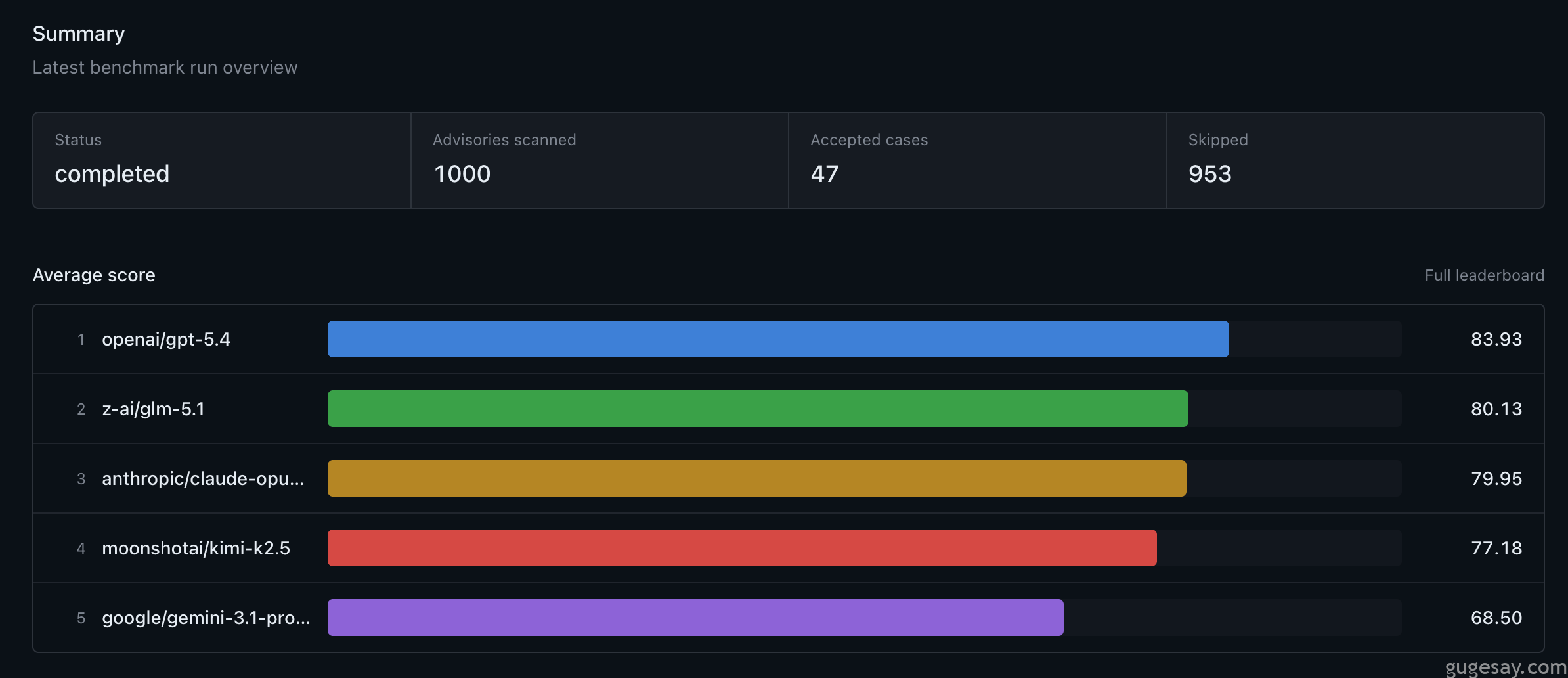
80%的准确率意味着什么?
模型能独立找到大部分漏洞位置,但还有大约五分之一会漏掉或误报。
这大概相当于什么呢?
一个初级安全工程师的水平。能干活,但还不能独当一面,需要人复核。
距离"完全自动化"还差点意思,但已经能当个不错的"第一道防线"用了——帮你快速过一遍代码库,标记可疑点,剩下的交给人判断。
效率提升是实实在在的。
几个有意思的观察
1. 闭源还是强
看榜单前三:OpenAI、Anthropic、智谱,全是闭源或半闭源模型。
不是说开源社区不行,而是复杂推理、多步分析这类能力,目前闭源大厂还是占优势。GPT系列能领先,很大程度上依赖更广泛的预训练数据和更精细的强化学习调优。
2. 国产模型不差
GLM-5.1拿到80分,这个成绩相当能打。
说明国内大模型在安全这个垂直领域同样有竞争力,不是只能做聊天机器人。安全场景对推理能力要求高,这块能做好,其他能力大概率也不差。
3. 月度更新,防止"作弊"
漏洞是动态的。如果benchmark常年不更新,模型可能会靠记忆"背答案",失去测试意义。
这个设计很聪明——每月刷新测试用例,让模型必须真的具备分析能力,而不是靠"我见过这道题"。
4. 才刚开始
47个有效测试用例,说多不多,说少不少。覆盖的语言和漏洞类型还需要扩充。
但方向是对的。🤝
安全研究员要失业了?
看到这儿,你可能想问:
既然AI找漏洞这么强了,安全研究员是不是可以转行了?
说笑的。
80%准确率意味着五分之一的情况会漏掉漏洞。在真实环境里,网络攻击者会用各种对抗手段、混淆技术绕过检测,这些"套路"AI不一定能识别。
而且找漏洞只是第一步。
找到漏洞之后,还需要判断它的实际影响(能利用吗?会造成什么后果?)、生成修复补丁、验证修复方案……这些环节的难度一点不比发现漏洞低。
但AI确实改变了效率。
以前安全研究员花几个小时才能扫完的代码库,模型几分钟就能过一遍。标记可疑点,人来做最终判断——这是生产力的质变,不是替代。
就像现在的医生看X光片,AI辅助读片,但最终诊断还是人来签字。
未来更可能的方向是:安全研究员 + AI助手 = 超级个体。
一个人能干以前一个团队的活儿。
写在最后
安全行业有个老说法:防御者永远比攻击者辛苦。
因为攻击者只需要找到一个点突破,防御者需要筑起整面城墙。但现在,AI这把刀开始帮防御者分担压力了——它可以不睡觉、不知疲倦地在代码里"巡逻",发现那些人类容易忽略的细节。
N-Day-Bench测的是AI找漏洞的能力,但它背后折射的是整个安全行业的变局。
漏洞研究不再只是少数人的专属技能。当AI开始参与这场游戏,游戏规则正在被改写。
你准备好和AI做队友了吗?
想看完整数据可以上:ndaybench.winfunc.com